Google Cloudの新DBMS、AlloyDB for PostgreSQLを触ってみた Vol.2
- AlloyDB
- AlloyDB for PostgreSQL
- DBMS
- PostgreSQL
Google Cloudの新DBMS、AlloyDB for PostgreSQLを触ってみた Vol.2
まえがき
こんにちは。開発部の高井(Peacock)です。
前回に引き続きAlloyDB連載の第2回として、以下の機能を試していきたいと思います。
- フェイルオーバー
- 読み取りプールの追加
- モニタリング(Query Insights含め)
フェイルオーバー(Failover)させてみる
まず始めに、DBMSでは(割と)標準的に搭載されいているフェイルオーバー(Failover)を試していきます。
確認のための準備として、事前に踏み台用インスタンス経由のpostgresコンソール画面に入っておきます。
ここからポチッと簡単にフェイルオーバーさせることができます。ではやってみます。
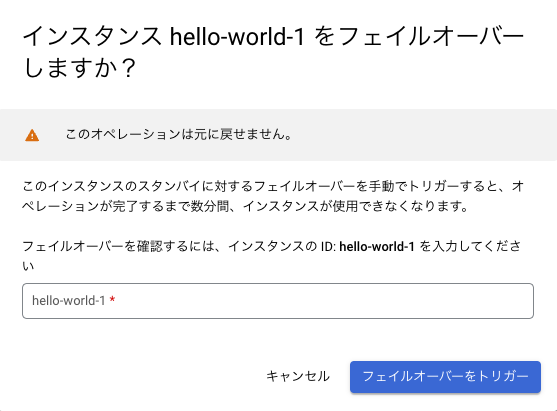
何事もなかったかのように繋がってしまいました。
読み取りプールの追加
注: ここからは前回使用したイギリスの全国不動産取引データを使って検証していきます
読み取りプール(Read Pool)とは
次に、Read Poolについてです。
こちらも他のDBMSを触ったことがある方には説明不要かもしれませんが、名前の通り読み取り専用のレプリカを作ることができます。
試してみる
では作ってみましょう。ここから1ボタンで作成できます。
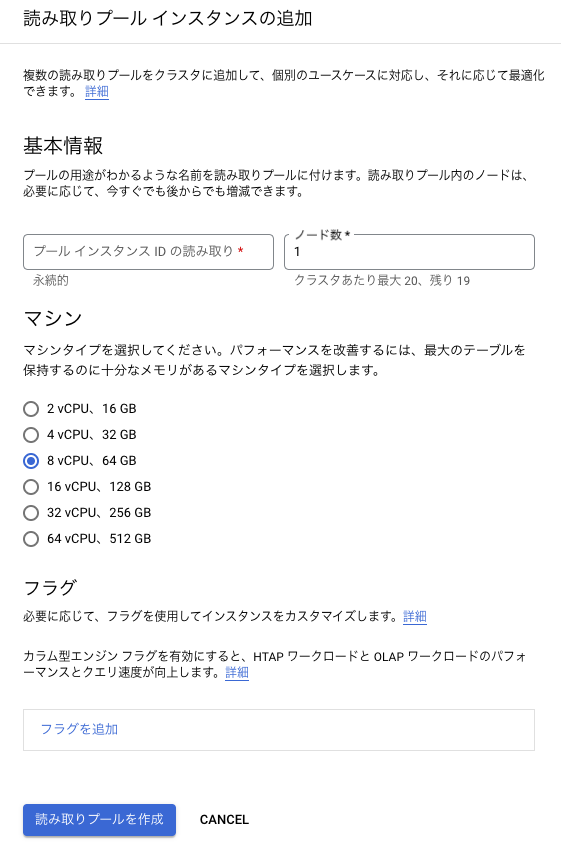
アクセスしてみます。例によって踏み台用インスタンスに接続し、出てきたIPにpsqlコマンドで繋ぎます。
適当にSELECTしてみます。
etude=> SELECT
AVG(t.price),
t.county,
t.property_type,
t.newly_built,
t.ppd_category_type
FROM
land_registry_price_paid_uk AS t
GROUP BY
t.county,
t.property_type,
t.newly_built,
t.ppd_category_type
LIMIT 10;
avg | county | property_type | newly_built | ppd_category_type
---------------------+------------------------------+---------------+-------------+-------------------
101900.871391076115 | AVON | D | f | A
100414.367631296892 | AVON | D | t | A
48973.011081794195 | AVON | F | f | A
47612.825136612022 | AVON | F | t | A
61260.467361111111 | AVON | S | f | A
58587.633245382586 | AVON | S | t | A
50561.262063845583 | AVON | T | f | A
51614.463157894737 | AVON | T | t | A
391744.902679024886 | BATH AND NORTH EAST SOMERSET | D | f | A
622014.147058823529 | BATH AND NORTH EAST SOMERSET | D | f | B
(10 rows)削除はできないことも確認してみましょう。
postgres=> DROP TABLE land_registry_price_paid_uk;
ERROR: cannot execute DROP TABLE in a read-only transaction
はい。こんな具合に読み取り専用のレプリカを追加することができました。
スロークエリを投げて最適化されているか検証
読み取りプールだと最適化されているか?
以下の重そうなクエリを投げて、読み取りプールで最適化されているか検証します。
SELECT
main.property_type,
main.newly_built,
main.duration,
main.city,
_avg.average,
_min.minimum,
_max.maximum
FROM
land_registry_price_paid_uk AS main
LEFT JOIN (
SELECT
property_type,
newly_built,
duration,
city,
AVG(price) AS average
FROM
land_registry_price_paid_uk
GROUP BY
property_type,
newly_built,
duration,
city) AS _avg ON main.property_type = _avg.property_type
AND main.newly_built = _avg.newly_built
AND main.duration = _avg.duration
AND main.city = _avg.city
LEFT JOIN (
SELECT
property_type,
newly_built,
duration,
city,
MIN(price) AS minimum
FROM
land_registry_price_paid_uk
GROUP BY
property_type,
newly_built,
duration,
city) AS _min ON main.property_type = _min.property_type
AND main.newly_built = _min.newly_built
AND main.duration = _min.duration
AND main.city = _min.city
LEFT JOIN (
SELECT
property_type,
newly_built,
duration,
city,
MAX(price) AS maximum
FROM
land_registry_price_paid_uk
GROUP BY
property_type,
newly_built,
duration,
city) AS _max ON main.property_type = _max.property_type
AND main.newly_built = _max.newly_built
AND main.duration = _max.duration
AND main.city = _max.city;
実際に計測したJupyter Notebookはこちらにあります。(計測実行には時間とメモリが結構必要なのでご注意ください)
具体的な実行結果については規約違反になるため触れられませんが、特に読み取りプールでも有意差は見られませんでした。
別途時間をとって違う確度から検証をしてみたいと考えています。
読み取りプールの削除
削除も同じ画面からできます。消してみます。
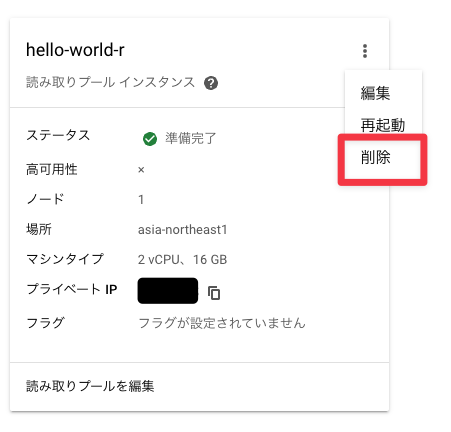
これでお掃除もできました。
モニタリング
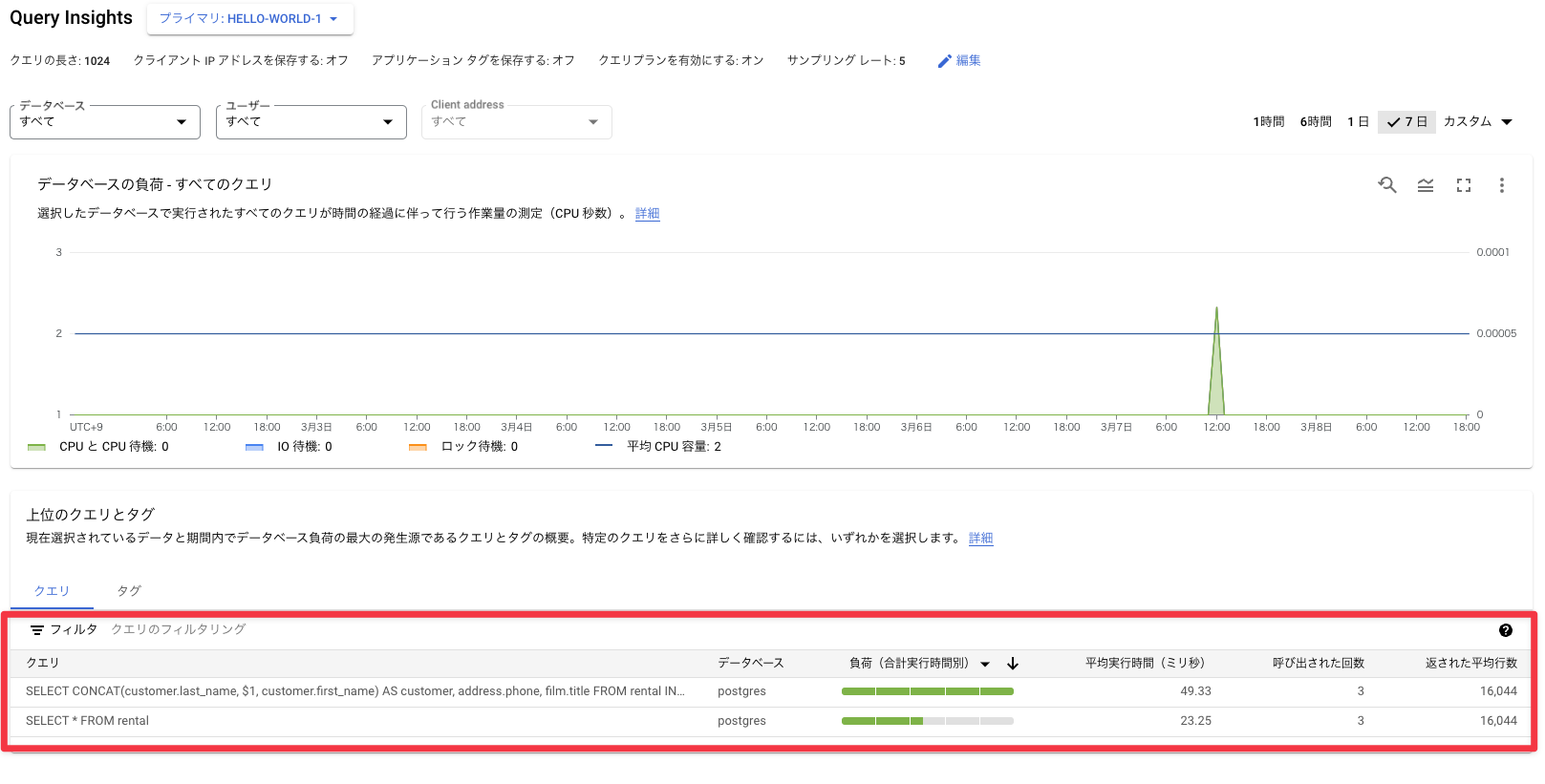
最後にモニタリングです。Google Cloudの他のDBMSを使ったことがある方にはおなじみですが、一通りの項目が見られます。
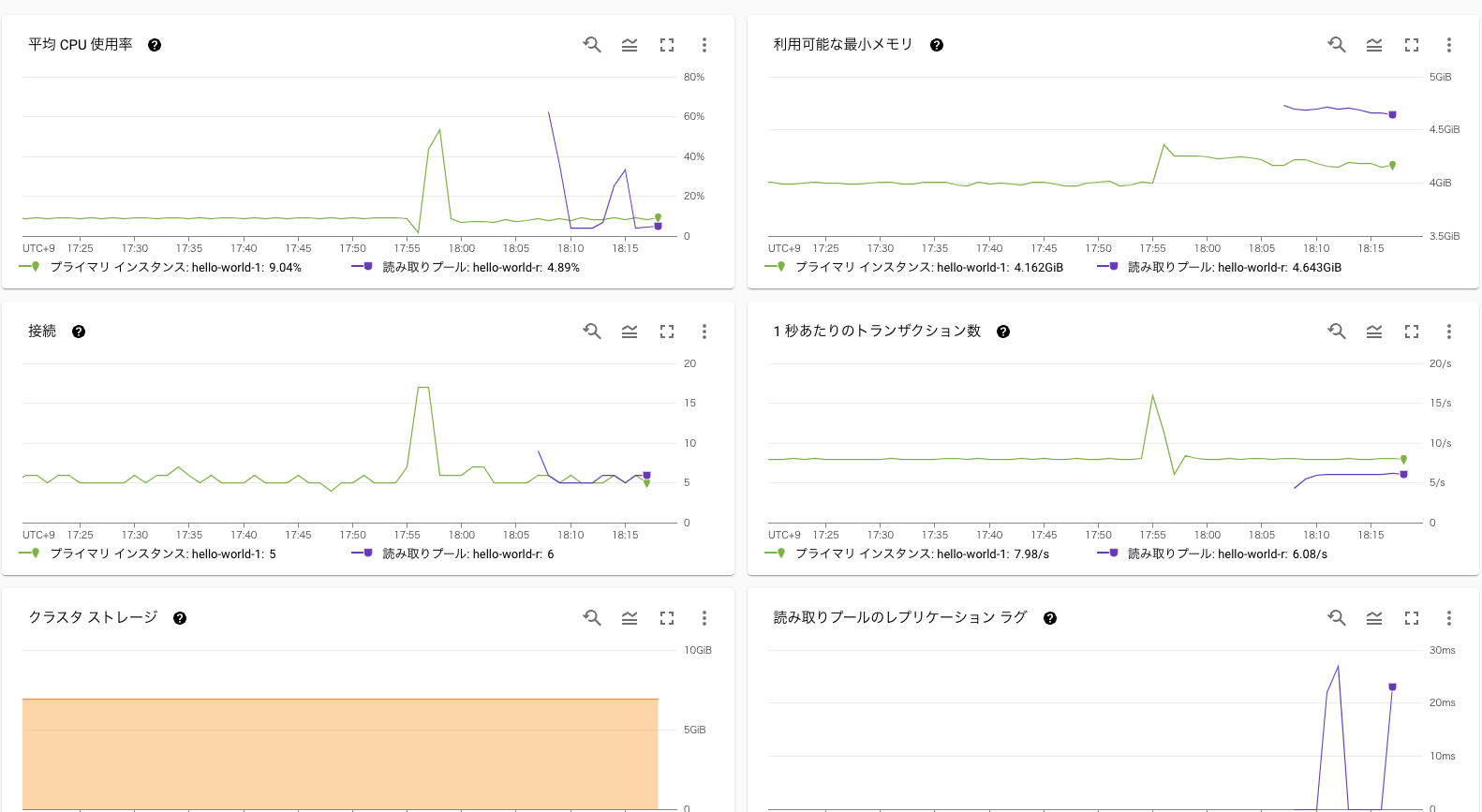
もちろんQuery Insightsの機能も使うことができます。どのクエリで負荷がかかっているかを分析できます。
まとめ
今回は第2回としてフェイルオーバー、読み取りプール、そしてモニタリング機能を試してみました。
次回はいよいよ第3回、バックアップ編ということで、ここ直近GAになったContinuous backup and recoveryも含めてバックアップ機能を試していく予定です。お楽しみに!