Document AI とは?非構造化データからインサイトを引き出す仕組みを徹底解説!
- AI
- AutoML
- Cloud
- ドキュメント
本記事は、2022年4月19日に開催された Google の公式イベント「 Google Cloud ML サミット」において、 Google Cloud の AI/ML スペシャリストである児玉敏男氏が講演された「 Document AI について」のレポート記事となります。
今回は Google が提供するビジネスソリューション「 Documtent AI 」について、市場背景を踏まえながらサービスの機能や仕組み、処理実行時の流れなど、あらゆる観点から一挙にご紹介します。
なお、本記事内で使用している画像に関しては、 Google Cloud ML サミット「 Document AI について」を出典元として参照しております。
それでは、早速内容を見ていきましょう。
ビジネスシーンにおけるドキュメントの現状
昨今、消費者ニーズは高度化かつ多様化しており、企業が顧客要望に応えて成長を遂げるためには、継続的なイノベーションが必要になります。
しかし、とある調査会社のレポートによれば、日本企業の社員は業務に必要な情報を得るためにドキュメントを参照するケースが多く、その情報を探し出すために多くの時間を費やしています。そして、情報検索に手間を掛けてしまい、組織としての生産性が低下します。
ただし、少し見方を変えると、企業が保有するドキュメントは宝の山であり、様々な情報が眠っていると言えます。

具体的なドキュメントの例としては、
- 電子メール
- PDF ファイル
- ファーム
- 画像データ
- 契約書
- 特許
などが挙げられます。
このように、大量のドキュメントが社内に存在している一方で、業務データの約 90% は非構造化データであり、そのうち 70% はメールや契約書などのテキスト形式となっています。そして、これらのドキュメントの意味を正しく理解できていないユーザーは数多く存在します。
そのため、ユーザーが構造化されていないテキストから有効な事実やインサイト(洞察)を取得するための、使いやすくスケーラブルなツールが求められています。
また、ビジネスが成長するにつれて、ドキュメントは次第に複雑化してきました。
例えば、
- 量
- 多様性
- 外部の知識
- 意味の深さ
など、これらの要素が増大または複雑化することで、ユーザーがドキュメントの意味を正確に理解することはさらに困難になりました。
一般的には、企業に存在するデータのうち、体系化されているものは全体の 20% 程度だと言われています。体系化されたデータとは、コンピューターが読み取れるように設計されており、検索できるようにフォーマットされているデータを指します。

そして、残りの約 80% は体系化されていないデータです。例えば、メール・文書といったテキストデータや衛星・監視カメラから取得した画像データなどが該当します。

これらの「体系化されていないデータ」を体系化できない状態では、自社が保有するデータの価値は半減してしまいます。このような背景から、企業はデータを体系化するための仕組みを強く求められているのです。

そして、今回ご紹介する Document AI がデータの体系化に大きく寄与します。ここからは、 Document AI の概要について詳しく見ていきましょう。
Document AI とは?
Document AI とは、非構造化データを構造化データに変換できる AI ツールです。機械学習を活用することで、体系化されていないドキュメントからインサイトを引き出すことができます。
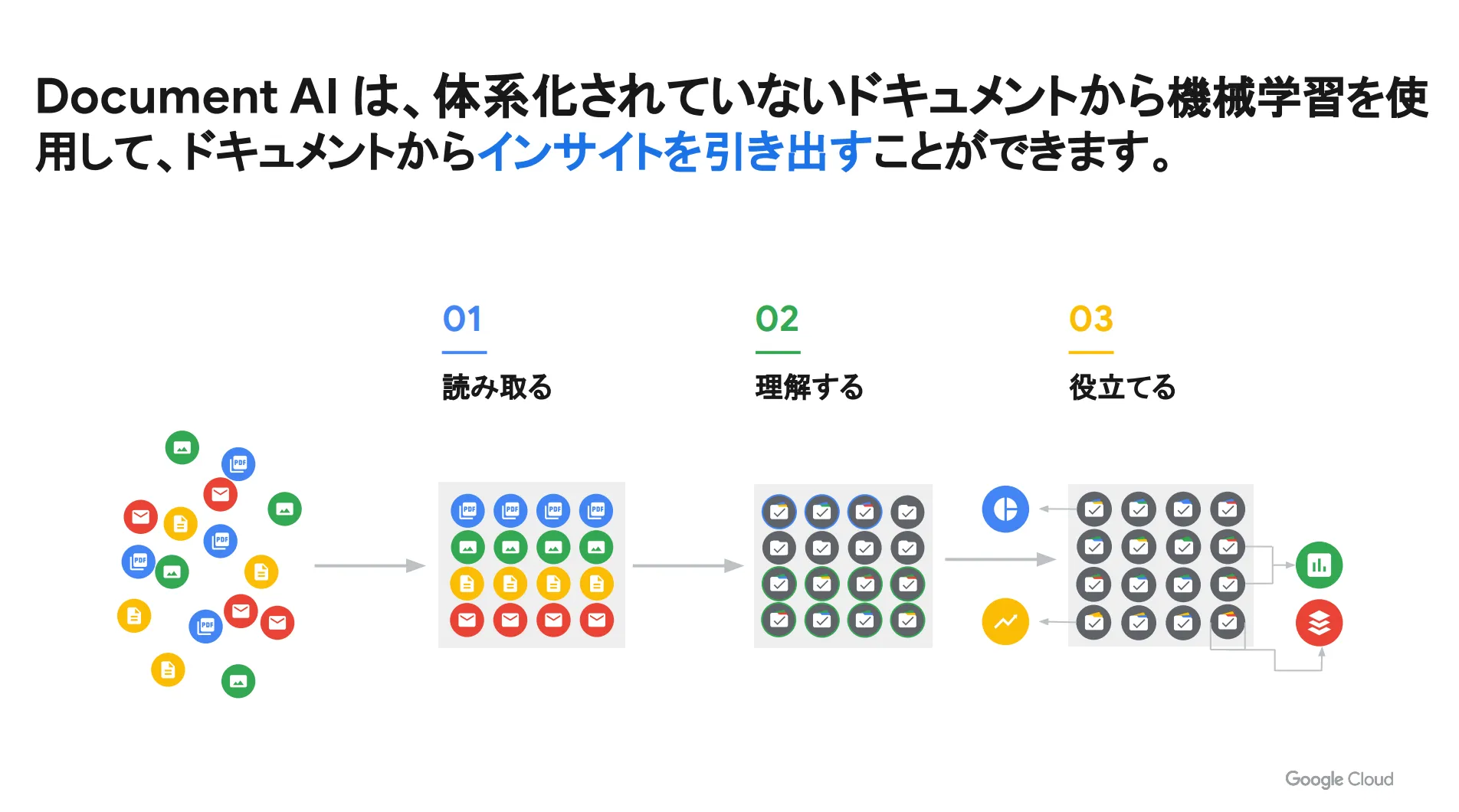
この Document AI の活用により、自社が保有しているデータの価値を最大限に引き出すことが可能です。つまり、ユーザーがドキュメントの正しい意味を理解できるようになる、ということです。

そして、 Document AI は既にあらゆる業界で使われています。業種を問わずに様々な企業が Document AI を導入し、自社のデータを有効活用しています。ドキュメントから読み取られたデータを活用することで、プロダクトに関する新たな分析情報を取得でき、顧客の期待に応えることが可能になります。

Document AI の導入事例
Quantiphi
Document AI を業務で活用している事例として、米国の大手金融サービス会社「 Quantiphi 」が挙げられます。従来、手作業で行なっていた業務を Document AI で自動化し、業務効率化を実現するとともに 97.8% という高い正確性を実現しています。

DocuSign
Document AI は DocuSign の電子取引用の自動タグ付けフォームにも活用されています。テキストの検出からドキュメントへのタグ適用まで、一気通貫したドキュメント処理を実行できます。
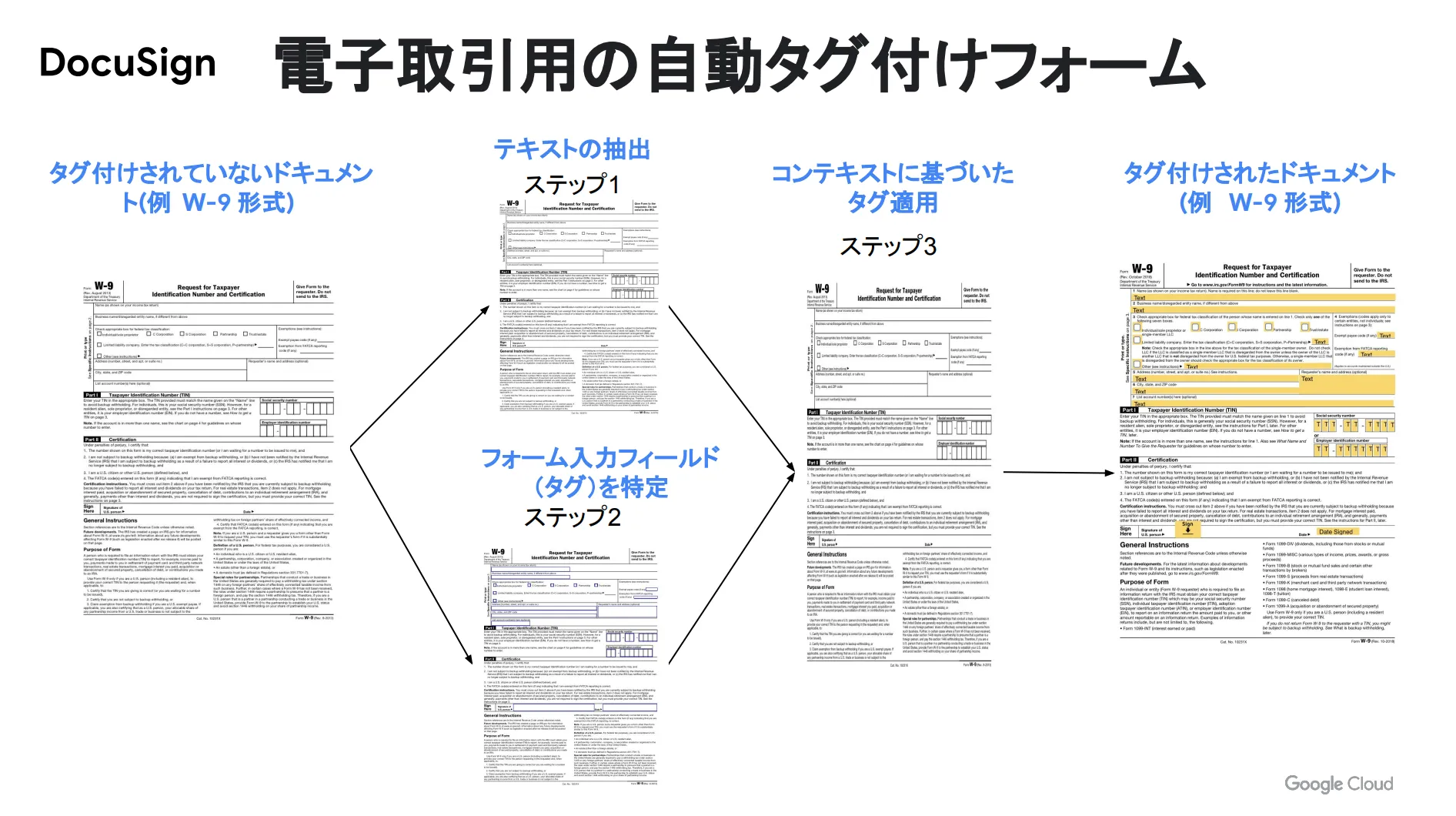
そして、 DocuSign のモバイルエンジニアリング責任者であるキラン・カザ氏は「 AutoML Natural Language 内にあるカスタムエンティティ抽出を使用することで、弊社のモデルをトレーニングするために大規模なデータセットを利用し、ドキュメントの出所に関係なく、処理を継続的に改善できます。」と語っています。
Document AI のテキスト検出技術
Document AI は、ドキュメントに対して人間のようにアプローチする、という特徴を持っています。 OCR (光学式文字認識)でテキストを読み取り、 Natural language や AutoML Natural Language で内容を理解します。
Document AI による読み取り
Document AI は最先端のディープラーニングニューラルネットワークアルゴリズムを使用しています。これにより、 Document AI をはじめとした Google Cloud (GCP)の OCR テクノロジーは、比類のない精度でテキストや画像を認識することができます。
そして、この Document AI による読み取りは「ベース OCR 」と「 Form Parser 」という2つの OCR テクノロジーに支えられています。それぞれについて詳しく見ていきましょう。
ベース OCR
ベース OCR はドキュメントから最新のテキストを抽出できます。世界クラスの精度を誇り、200の言語をサポートしていることに加えて、 PDF や GIF 、 PNG など、様々な種類のドキュメントおよび画像に対応しています。

Form Parser
Form Parser はドキュメントから空間構造を抽出できます。 OCR を介して複雑なドキュメントをフィードし、その構造を保持できることに加えて、 key value ペアを抽出したり、表形式のコンテンツで作業したりすることが可能です。

Document AI による理解
Document AI を活用することで、体系化されていないドキュメントから貴重な見解を引き出すことができます。
そして、この Document AI による理解は「 Natural Language API 」と「 Vertex AI AutoML Natural Language 」という2つのテクノロジーに支えられています。それぞれについて詳しく見ていきましょう。
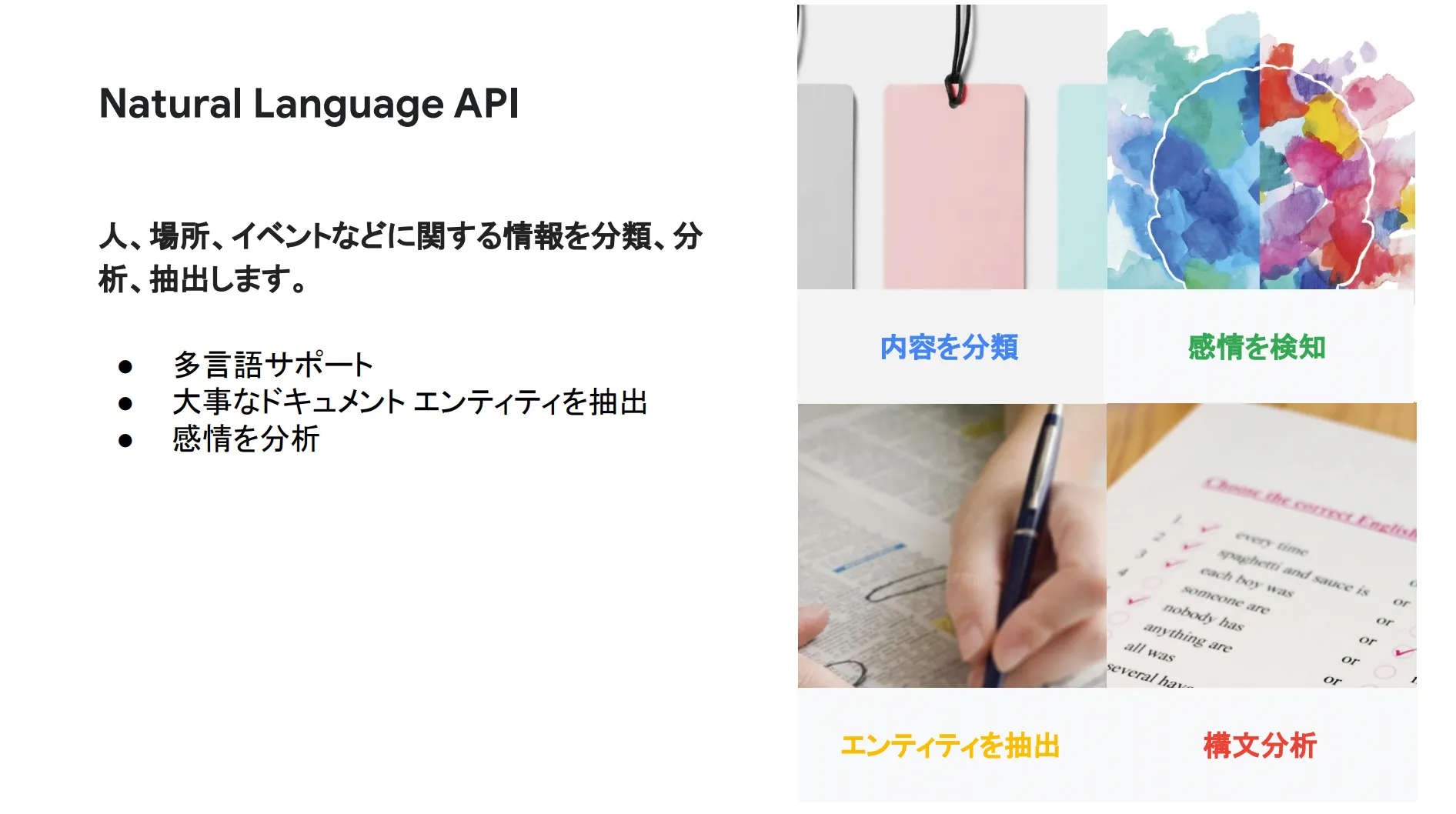
Natural Language API
Natural Language API は、内容分類や感情検知など様々な機能を提供しています。多言語をサポートしており、重要なドキュメントエンティティを抽出することができます。
Natural Language API の活用事例や詳細情報について理解を深めたい方は以下の記事がオススメです。
Google Cloudの「Natural Language API」で顧客の声をネガポジ判定する方法をご紹介!
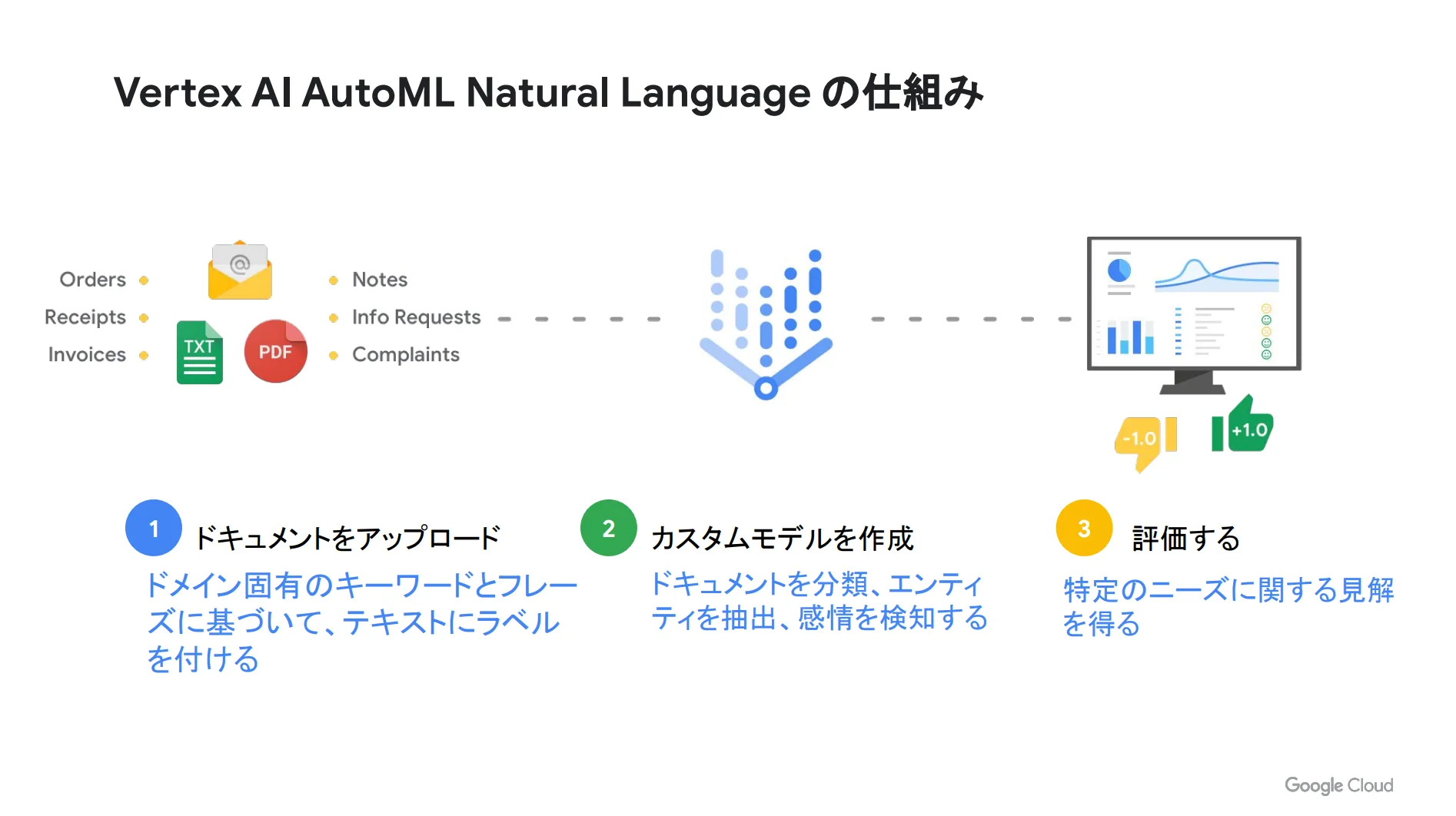
Vertex AI AutoML Natural Language
Vertex AI AutoML Natural Language の仕組みは下図の通りです。ドキュメントをアップロードした後にカスタムモデルを作成し、最後に評価を行います。
Document AI によるドキュメント処理の流れ
最後に Document AI によるドキュメント処理の流れを見ていきましょう。今回は特許ドキュメントのライフサイクルを例にとってご説明します。
例えば、 Document AI と AutoML を併用して活用する場合、特許ドキュメントのライフサイクルは下図のようになります。
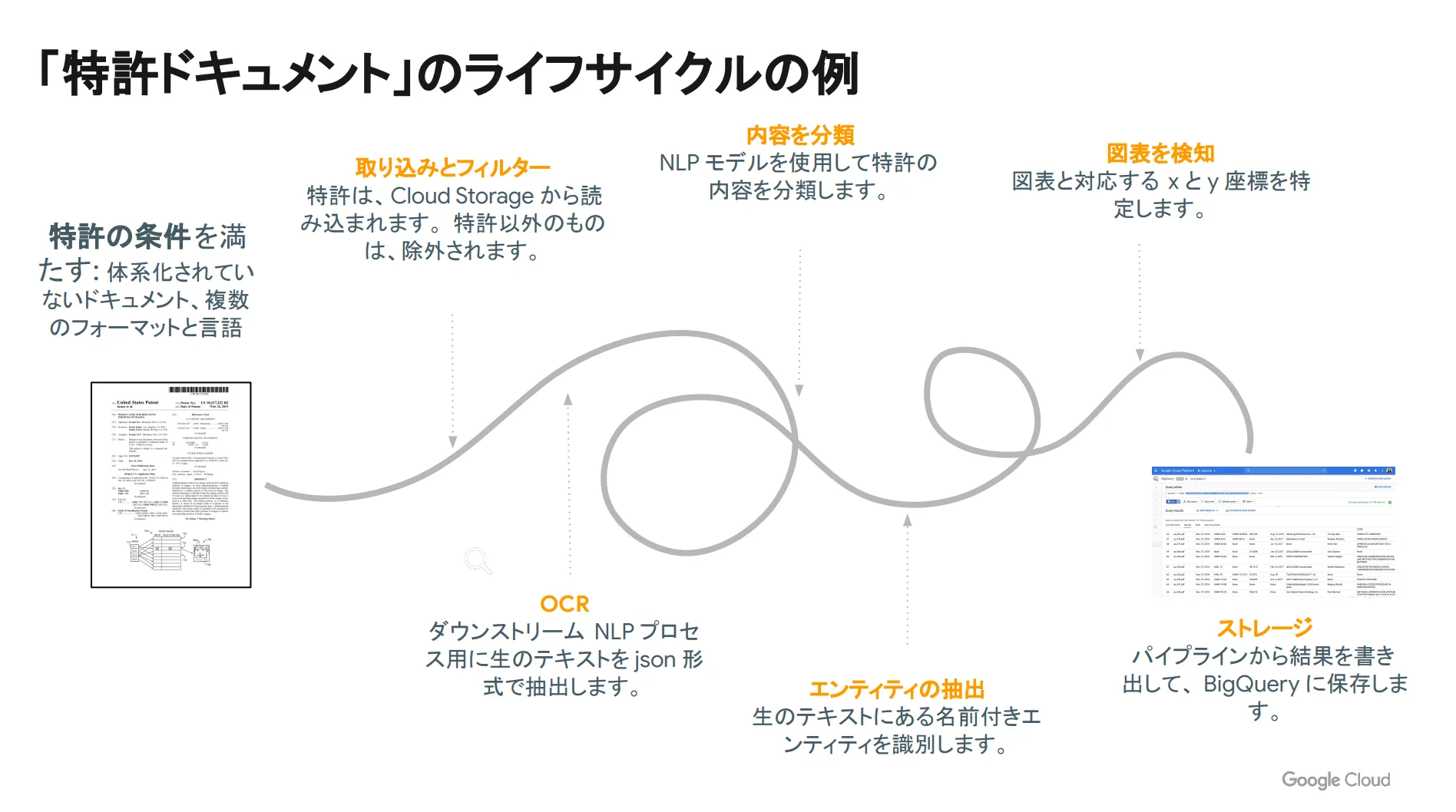
まずは入力画像となる PDF ファイルを画像に変換した後、 AutoML Vision により特許ドキュメントとその他のドキュメントに分類します。
次にベース OCR を実行し、各ドキュメントからテキストを抽出します。下図の左側が元々のドキュメントであり、右側がテキスト抽出後のドキュメントです。オリジナルのドキュメントからテキストのみが抽出されていることがわかります。

次に抽出したテキストを基にして、 NLP モデルの分類機能で特許の内容を分類・整理します。下図の左側が元々のドキュメントですが、この内容はコンピュータビジョンに関するコンテンツがメインであることがわかります。

また、抽出したテキストから各エンティティを抜き出します。下図の左側が元々のテキストであり、右側が抽出されたエンティティです。発行日や分類、申請番号など、要素ごとにエンティティが抽出されています。

次に AutoML の物体検知により、特許についての図表やグラフを抽出します。下図左側の下部が抽出された図表であり、元々のドキュメントから座標を戻していることがわかります。

そして最後に、抽出した結果を BigQuery に保存します。抽出されたデータを本当の値と比較し、一連の処理の精度を検証します。

このように、 Document AI と AutoML のソリューションを併用して特許ドキュメントを自動的に処理することで、最終的に BigQuery に処理結果が保存され、ドキュメントのデータを活用するための準備が整います。
Document AI に関する Q&A
Q.Document AI の日本語対応はいつ頃の予定ですか?
A.Document AI には多くの機能が搭載されていますが、通常の OCR や自然言語処理については2022年4月現在で既に日本語に対応しています。なお、一部日本語に対応していない機能もあるので、この部分は今後のアップデートにご期待ください。
Q.日本語の文書を正しく読み取るコツはありますか?
A.人間の目にハッキリと見える画像は高い精度で読み取ることができます。そのため、可能な限り鮮明なものを使用するのが良いでしょう。
Q.日本語の請求書などの読み取り精度はどの程度ですか?
A.感覚値として、7割程度は正確に読み取ることができると思います。
Q.Document AI の Natural Language はどのような場面で利用されますか?
A.様々なユースケースが想定されますが、例えば小売業における商品アンケートの分析などが挙げられます。
まとめ
今回は Google が提供するビジネスソリューション「 Documtent AI 」について、市場背景を踏まえながらサービスの機能や仕組み、処理実行時の流れなど、あらゆる観点から一挙にご紹介しました。
昨今、消費者ニーズは高度化かつ多様化しており、企業が顧客要望に応えて成長を遂げるためには、自社に眠るドキュメント情報を有効活用する必要がありますが、うまく情報を取得できていない企業は一定数存在します。
せっかく情報を保有していても、有効に活用できなければその価値は薄れてしまうため、ドキュメントの情報を正しく把握し、そのデータを有効活用するための仕組みが重要になります。
この記事でご紹介した Document AI は、ドキュメント処理を効率化する上でとても有効なソリューションになります。機械学習を活用した高精度な処理を実現でき、直感的に扱える使いやすいサービスだと言えます。
本記事を参考にして、ぜひ Document AI の活用を検討してみてはいかがでしょうか?
弊社トップゲートでは、Google Cloud (GCP) 利用料3%OFFや支払代行手数料無料、請求書払い可能などGoogle Cloud (GCP)をお得に便利に利用できます。さらに専門的な知見を活かし、幅広くあなたのビジネスを加速させるためにサポートをワンストップで対応することが可能です。
Google Workspace(旧G Suite)に関しても、実績に裏付けられた技術力やさまざまな導入支援実績があります。あなたの状況に最適な利用方法の提案から運用のサポートまでのあなたに寄り添ったサポートを実現します!
Google Cloud (GCP)、またはGoogle Workspace(旧G Suite)の導入をご検討をされている方はお気軽にお問い合わせください。
メール登録者数3万件!TOPGATE MAGAZINE大好評配信中!
Google Cloud(GCP)、Google Workspace(旧G Suite) 、TOPGATEの最新情報が満載!