こんなに簡単にできるの? BigQuery ML で教師ラベルなしで異常検出する3つの方法とは?
- BigQuery ML
本記事は、2021年11月11日に開催された Google の公式イベント「 Google Cloud ML サミット」において、グーグル・クラウド・ジャパン合同会社のカスタマーエンジニアである葛木美紀氏が講演された「 BigQuery ML:教師ラベルなしで異常検出する3つの方法」のレポート記事となります。
今回は Google Cloud (GCP)に搭載されている BigQuery ML を活用して、教師ラベルなしで異常検出する方法をご紹介します。専門知識がなくても SQL で機械学習モデルを構築できる機能を使った実践的なアプローチのご紹介です。ぜひ最後までご覧ください。
なお、本記事内で使用している画像およびソースコードに関しては、 Google Cloud ML サミット「 BigQuery ML:教師ラベルなしで異常検出する3つの方法」を出典元として参照しております。
それでは、早速内容を見ていきましょう。
BigQuery ML による異常検出の概要
BigQuery ML (BQML)とは?
BigQuery とは Google Cloud (GCP)で提供されているビッグデータ解析サービスです。通常では長い時間かかるクエリを数 TB (テラバイト)、数 PB (ペタバイト)のデータに対し数秒もしくは数十秒で終わらせることができます。
BigQuery はクラウドで提供されているため、サーバーレスでスケーラビリティがあり、非常にコストパフォーマンスに優れています。他の多彩な Google Cloud (GCP)の提供するサービスともシームレスに連携もでき、扱いやすいサービスの一つです。
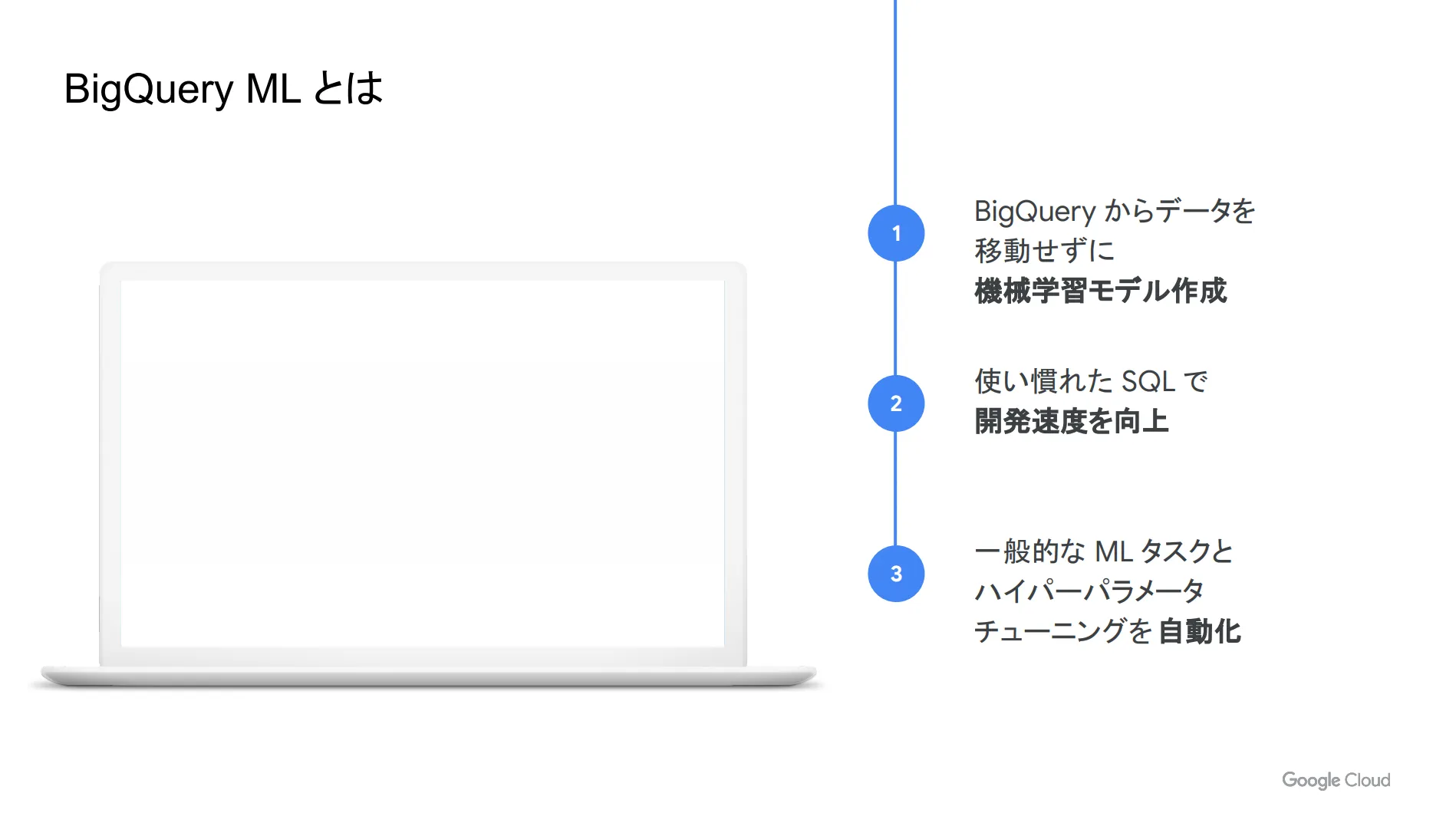
この BigQuery には BigQuery ML (BQML)という機械学習機能が組み込まれており、 BQML を活用することで手間なく異常検出を行うことができます。使い慣れた SQL で開発速度の向上を実現できるのはもちろん、一般的な機械学習タスクとハイパーパラメータチューニングを自動化することも可能です。
BigQuery に関心のある方は以下の記事がオススメです。
超高速でデータ分析できる!専門知識なしで扱えるGoogle BigQueryがとにかくスゴイ!
機械学習モデル作成にかかる工数
通常、機械学習モデルを作成するためには、様々な場所からデータを移動して加工する必要があります。また、 PC や VM のデータアクセスポリシーを設定するなど、セキュリティの観点も考慮しなければいけません。

その点、 BQML は BigQuery 上のデータをそのまま SQL で処理できるため、生産性が大きく向上します。機械学習の専門的な知識は必要なく、簡単な SQL で手軽にモデルを作成できる点も嬉しいポイントです。
BigQuery ML でサポートされているモデル
BigQuery ML (BQML) では以下のモデルがサポートされており、分類や回帰だけでなく、モデル管理を行うことも可能です。今回は下図で赤く塗りつぶしている部分の比較的新しい機能を使って異常検出する方法を詳しく解説します。

異常検出のユースケース
ここで、異常検出のユースケースをご紹介します。
異常検出は業界問わずに様々なシーンで活用されており、代表的なものとしては
- 金融業界での不正検出
- 小売業界での需要予測
- コンピューターネットワークにおける侵入検知
- 医療業界における障害検出
など、その種類は多岐にわたります。
一般的な異常検出のアプローチ
異常検出を行う際に問題になるのが、「異常」というステータスの定義が難しいことです。まずは、何がどのような状態になったら異常とするのか?を決めておくことが大切です。
既に異常の定義がなされており、データに「異常」または「正常」のラベルが付いている場合は、過去のラベル付データを活用して異常値を判断する「教師あり」の機械学習モデルを使うことになります。
その一方で、異常の定義がなされておらず、ラベル付データが存在しない場合は「教師なし」の機械学習モデルを活用し、データの性質に基づいて異常値を特定する必要があります。
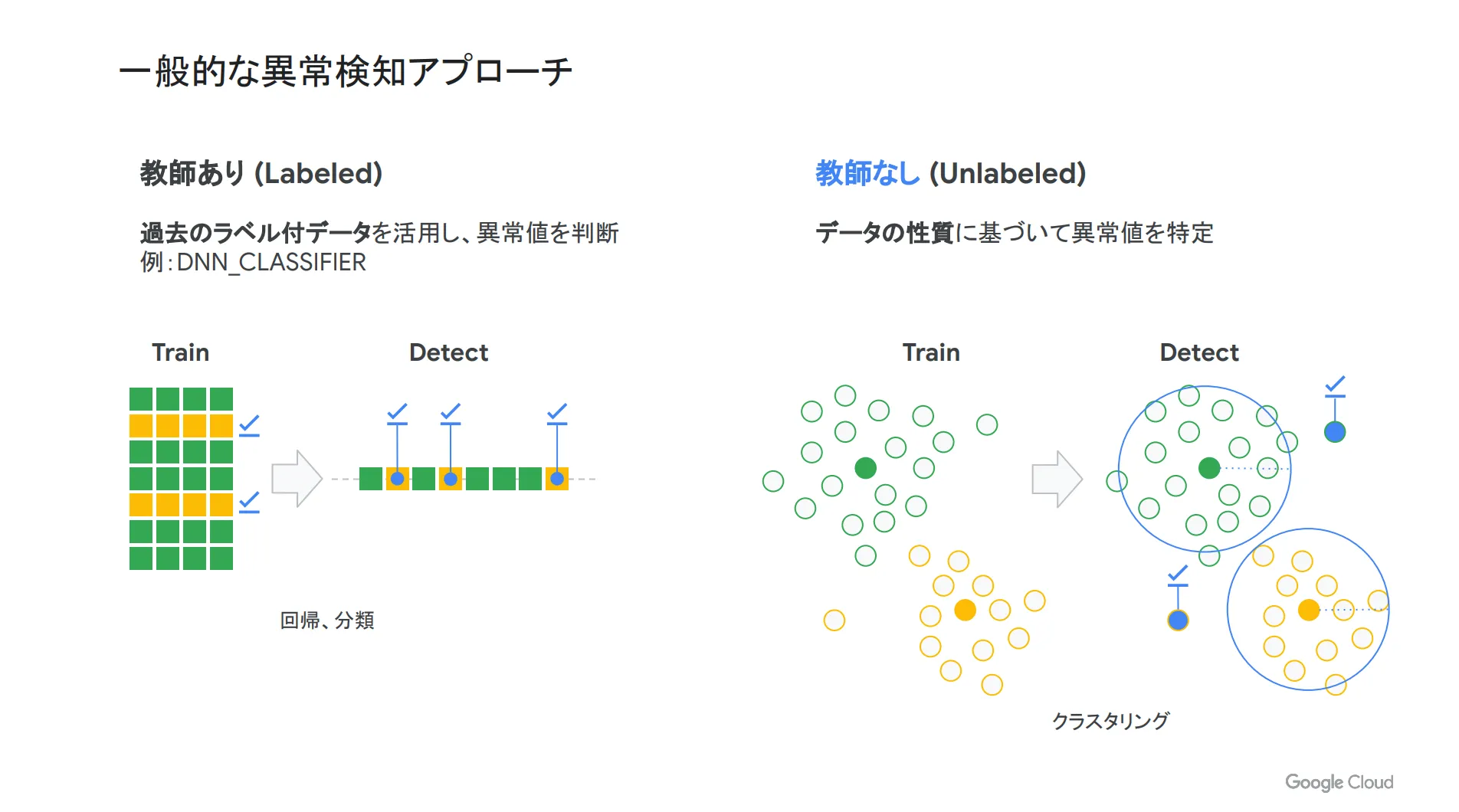
BigQuery ML の教師なし異常検出
前項でご説明した、教師なしの機会学習モデルを BigQuery ML (BQML) で構築するためには、以下3つのアプローチがあります。大きく分けると、時系列データに対しては ARIMA_PLUS を活用し、それ以外は k-means クラスタリングまたはオートエンコーダを使います。

次章以降では、この3つのアプローチについて、それぞれ詳しくご紹介します。
ARIMA_PLUS 時系列モデル
時系列データの異常検知
時系列データとは、時間の経過とともに定点観測されたデータを指す言葉です。例えば、下図は YouTube のとある動画のコメント数をグラフ化したものであり、日付や時間が横軸、1分ごとのコメント数が縦軸になっています。
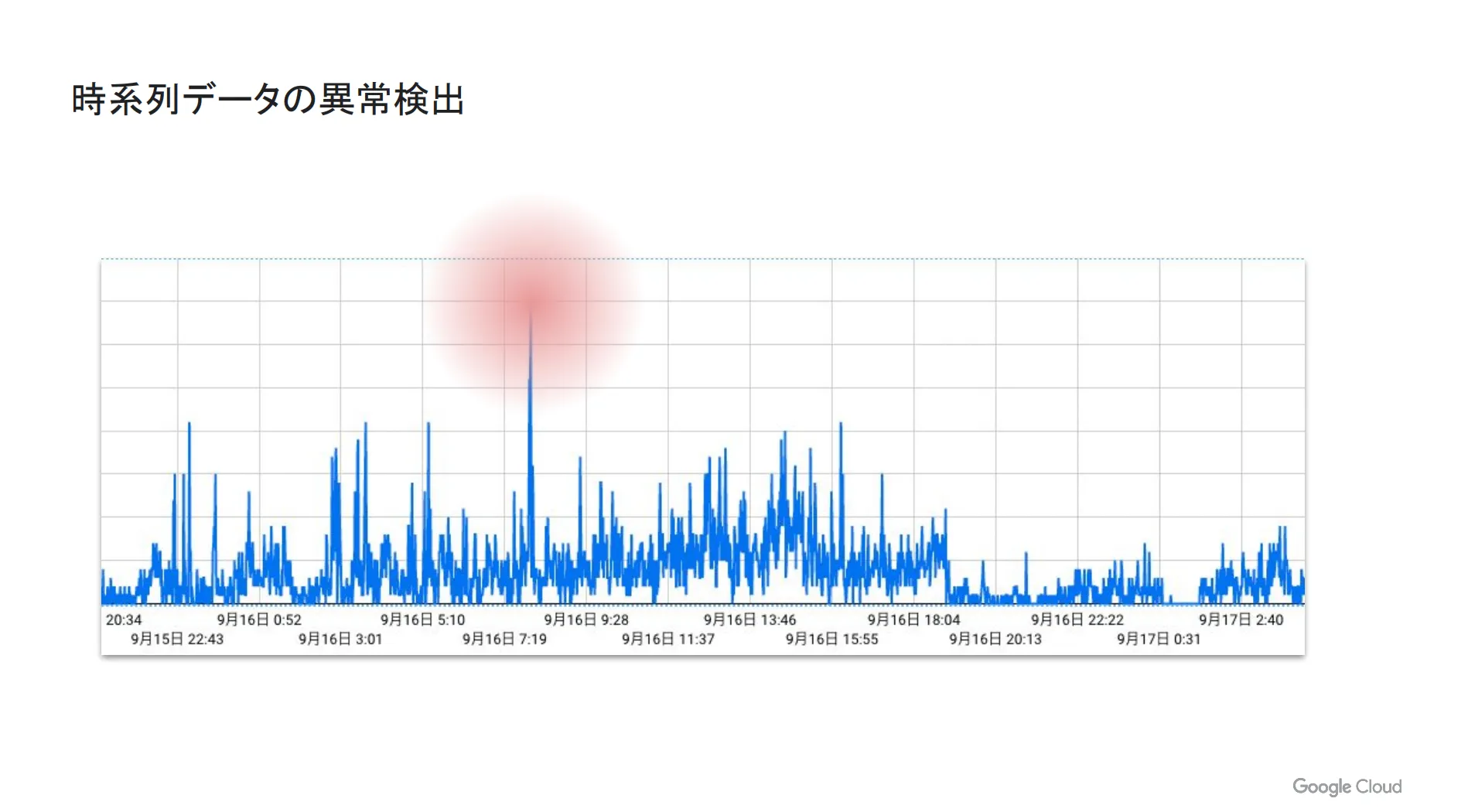
ここでグラフ全体を見てみると、赤丸の部分が大きく飛び跳ねており、他の時間帯と比較してコメント数が多いことがわかります。時系列データを見るときはパターンを考慮することが多いですが、このように明らかに突出した値を示しているものを異常値として見なすわけです。
そして、異常値の検出を客観的かつ自動的に行うために、 BigQuery ML (BQML) で時系列がどのように遷移していくのか、という予測を行い、そこから大きく外れるものを異常値として定義するのが ARIMA_PLUS 時系列モデルの基本的なアプローチになります。
ARIMA_PLUS モデルの作成例
ここでは、 ARIMA_PLUS モデルの作成例をご紹介します。以下、実際のコードを掲載していますので参考にしてください。 CREATE MODEL や OPTIONS など、要素ごとに必要情報を指定して、モデルを作成していきます。
CREATE MODEL anomaly.comment_arima_model
OPTIONS
(model_type = 'ARIMA_PLUS',
time_series_timestamp_col = 'dt',
time_series_data_col = 'cnt'
) AS
SELECT
*
FROM anomaly.comm_ts
ML.DETECT_ANOMALIES による異常検出
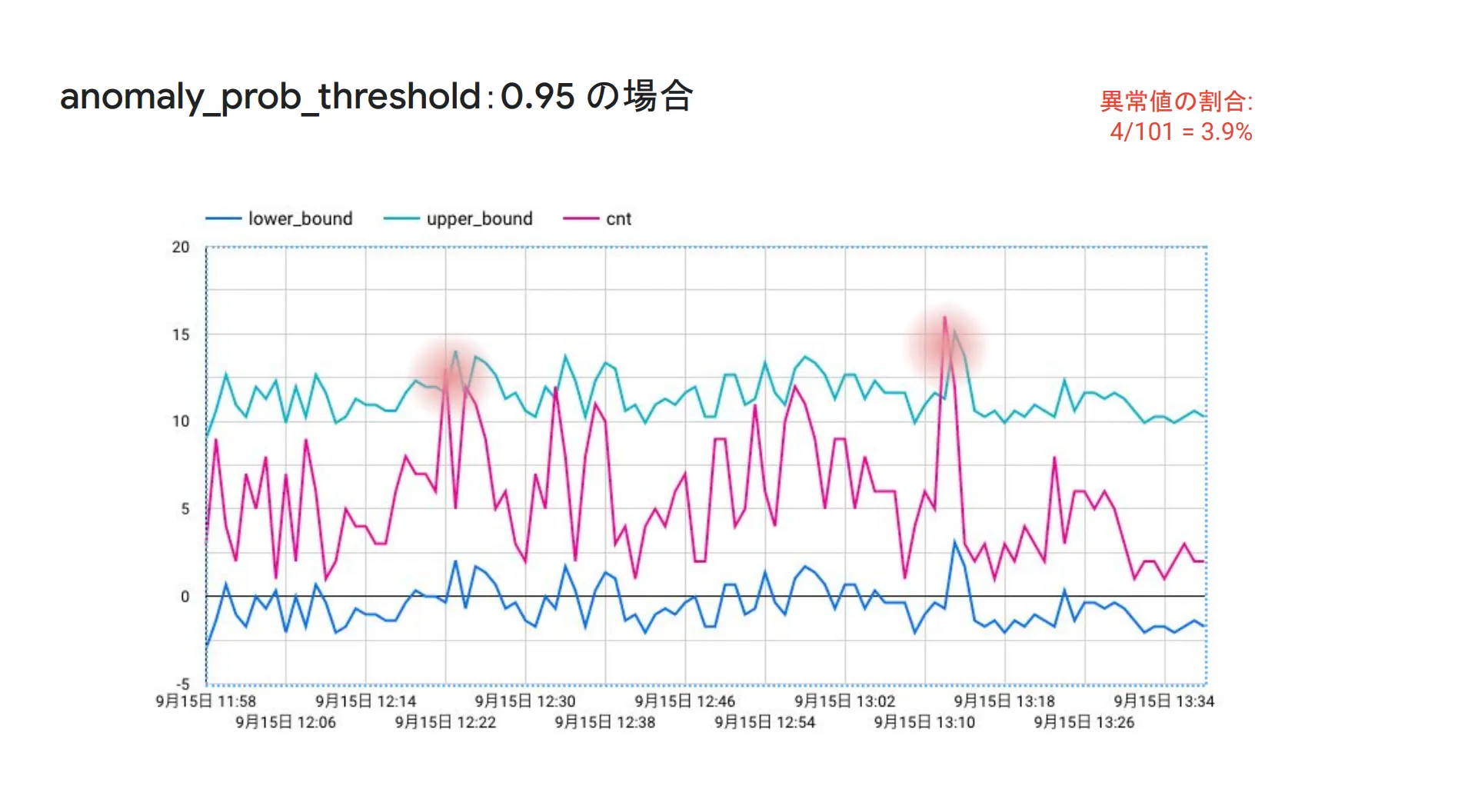
モデルを作成した後、実際の異常検出を行うためには ML.DETECT_ANOMALIES というものを使います。下図が実際の画面になりますが、0.95の部分が信頼区間を表しており、この区間から外れた部分が異常値として検出されます。
グラフの青線が実際のコメント数であり、緑線が信頼区間の上限値、黄線が信頼区間の下限値を示しています。つまり、真ん中の青線が緑線または黄線からはみ出している部分が異常値になります。なお、信頼区間の値を変えることで、異常検出の精度を厳しくしたり緩くしたり、状況に合わせて調節することが可能です。
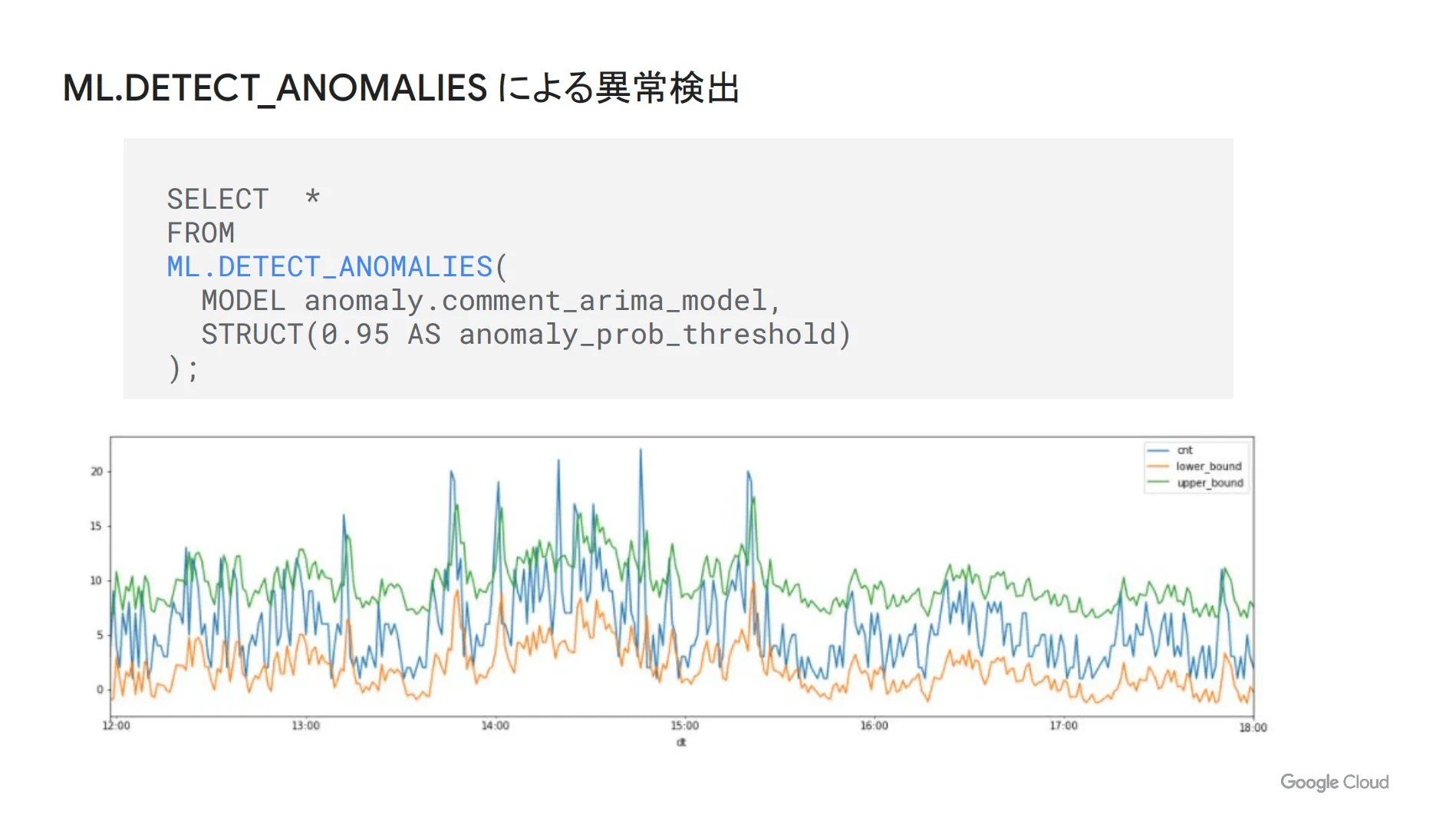
上図は PDF を貼り付けしているため、改めて異常検出のソースコードを記載します。
SELECT *
FROM
ML.DETECT_ANOMALIES(
MODEL anomaly.comment_arima_model,
STRUCT(0.95 AS anomaly_prob_threshold)
);
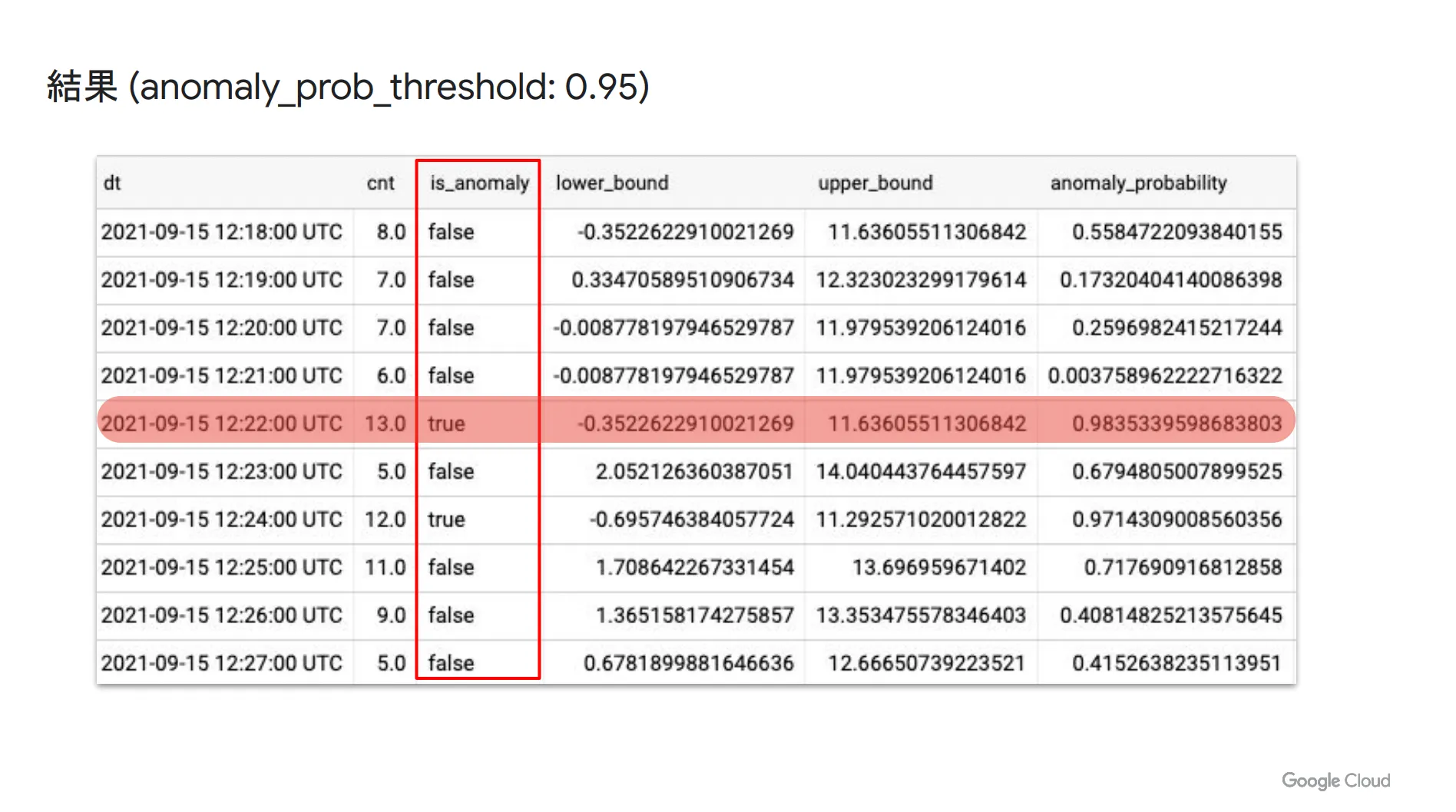
そして、信頼区間0.95で異常検出をした結果が以下の通りです。 is_anomaly というカラムが true になっているもの(赤枠で囲っている部分)が異常値として検出されたものになります。
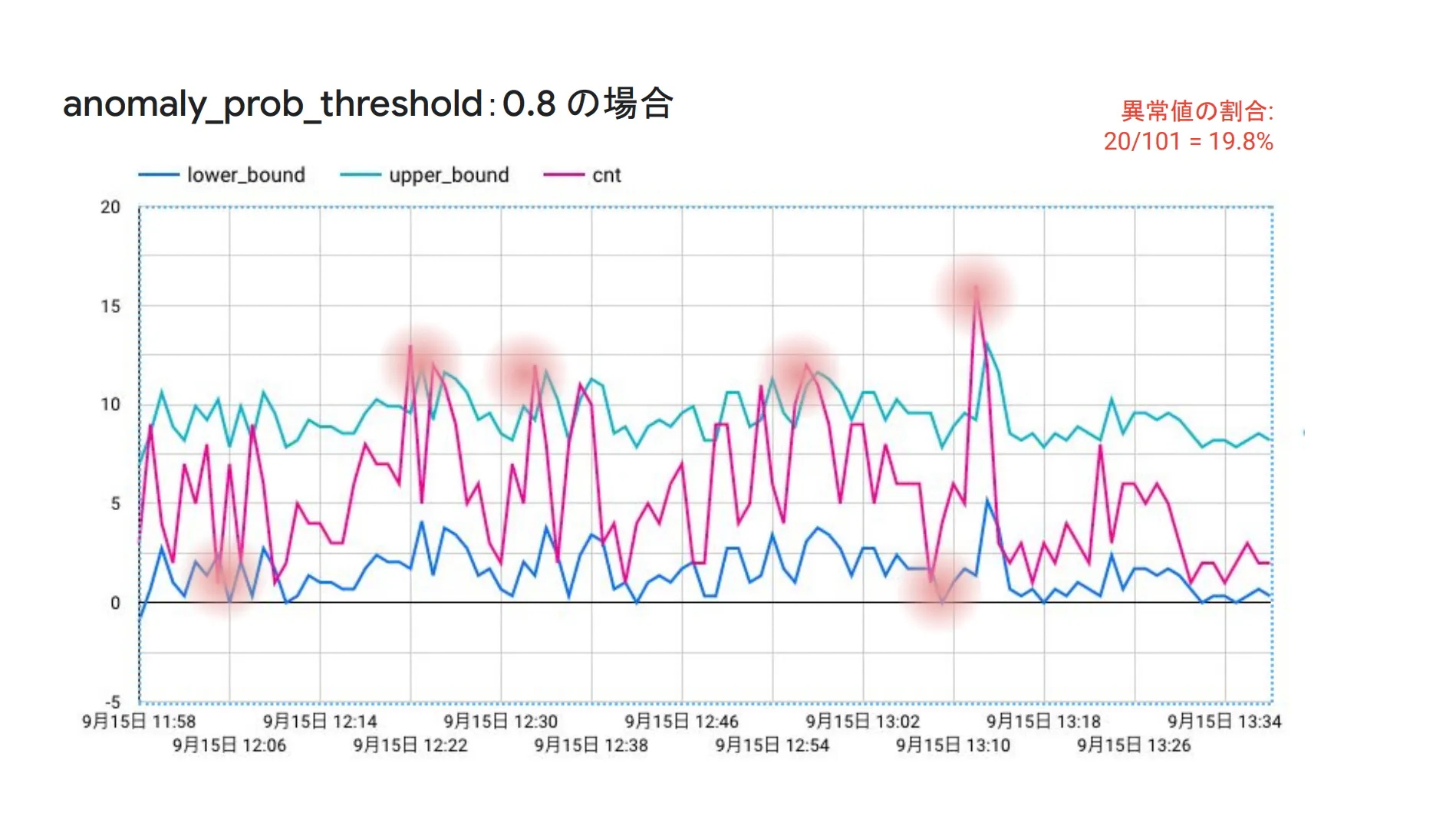
以下は、信頼区間を 0.95 および 0.8 に設定したときの異常値のグラフ比較です。0.95の場合は異常値の割合が全体の 3.9% ですが、0.8に設定した場合は 19.8% と、一気に異常値の割合が増加したことがわかります。
ここまで、時系列データに関するご説明をしましたが、時系列データ以外の場合でも、この閾値という考え方が重要になります。次章以降で詳しく見ていきましょう。
時系列データの活用に関心のある方は以下の記事がオススメです。
過去データから将来を予測する「時系列予測」とは何か?概要、メリット、種類、活用事例まで一挙に紹介!
こんなに簡単にできるの? Google Cloud (GCP)を活用した時系列分析のやり方を徹底解説!
k-means クラスタリング
k-means クラスタリングとは?
k-means クラスタリングは、教師なし機械学習における最もシンプルなアプローチの一つです。データをクラスターに分割して分析し、データポイントがクラスターの中心から一定距離外れている場合は異常とみなす仕組みとなっています。

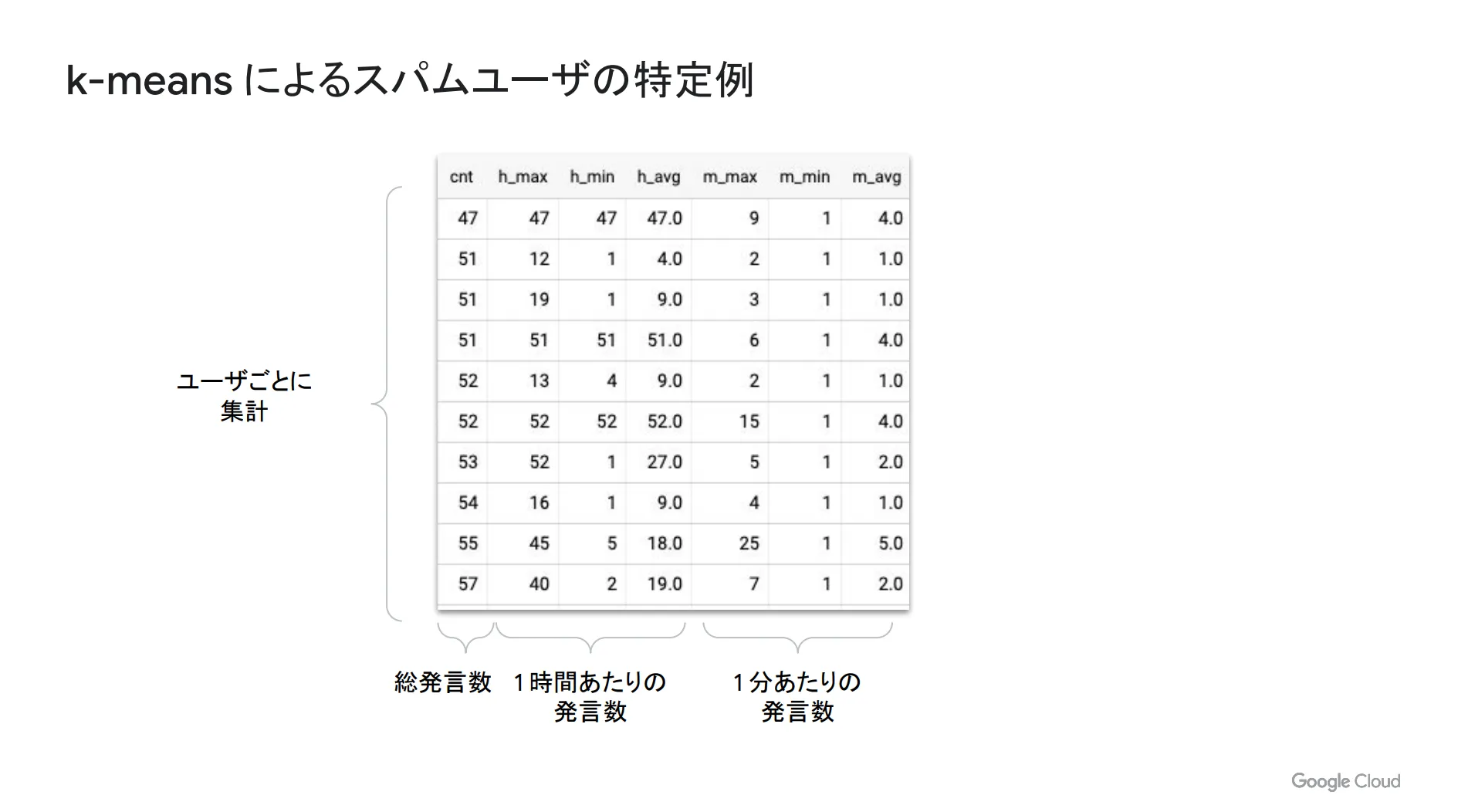
k-means によるスパムユーザーの特定例
ここで、具体的なデータを例にとってご説明します。以下は先ほどと同じようにとある動画のコメント数を表したものです。縦の1つの行が1ユーザーの発言数に対応しており、横に時間単位ごとの発言数が並んでいます。
k-means クラスタリングのモデル作成
上記の表を k-means クラスタリングでグループ分けします。以下が実際のコード例となっており、 先ほどの ARIMA_PLUS モデルと同様に、モデル名や OPTIONS を指定します。そして、モデルタイプには k-means を指定し、初期値は kmeans++ に設定しています。
#Query for model training
CREATE OR REPLACE MODEL anomaly.kmeans_model
OPTIONS(
model_type='kmeans',
kmeans_init_method = 'kmeans++'
)
AS
SELECT * EXCEPT(name,spam)
FROM
anomaly.spam_cnt;
ML.DETECT_ANOMALIES による異常検出
ここで、 ARIMA_PLUS モデルのときと同じように ML.DETECT_ANOMALIES を使って異常検知を行います。大きく異なるのは閾値設定であり、 ARIMA_PLUS モデルでは AS anomaly_prob_threshold となっていた部分が、 k-means クラスタリングでは AS contamination となっています。
#Query for creating anomaly detection results
SELECT
* EXCEPT(name, CENTROID_ID)
FROM
ML.DETECT_ANOMALIES(
MODEL anomaly.kmeans_model,
STRUCT(0.05 AS contamination),
TABLE anomaly.spam_cnt
)
WHERE is_anomaly = true;
contamination パラメータの考え方
前項で出てきた contamination の考え方ですが、これは「全体の中で異常がどのくらいあるのか」を示すパラメータです。例えば、全体の 20% が異常だと考える場合は contamination の値を 0.20 に設定します。この contamination の値を変えることで、異常検出の精度を調整することができます。

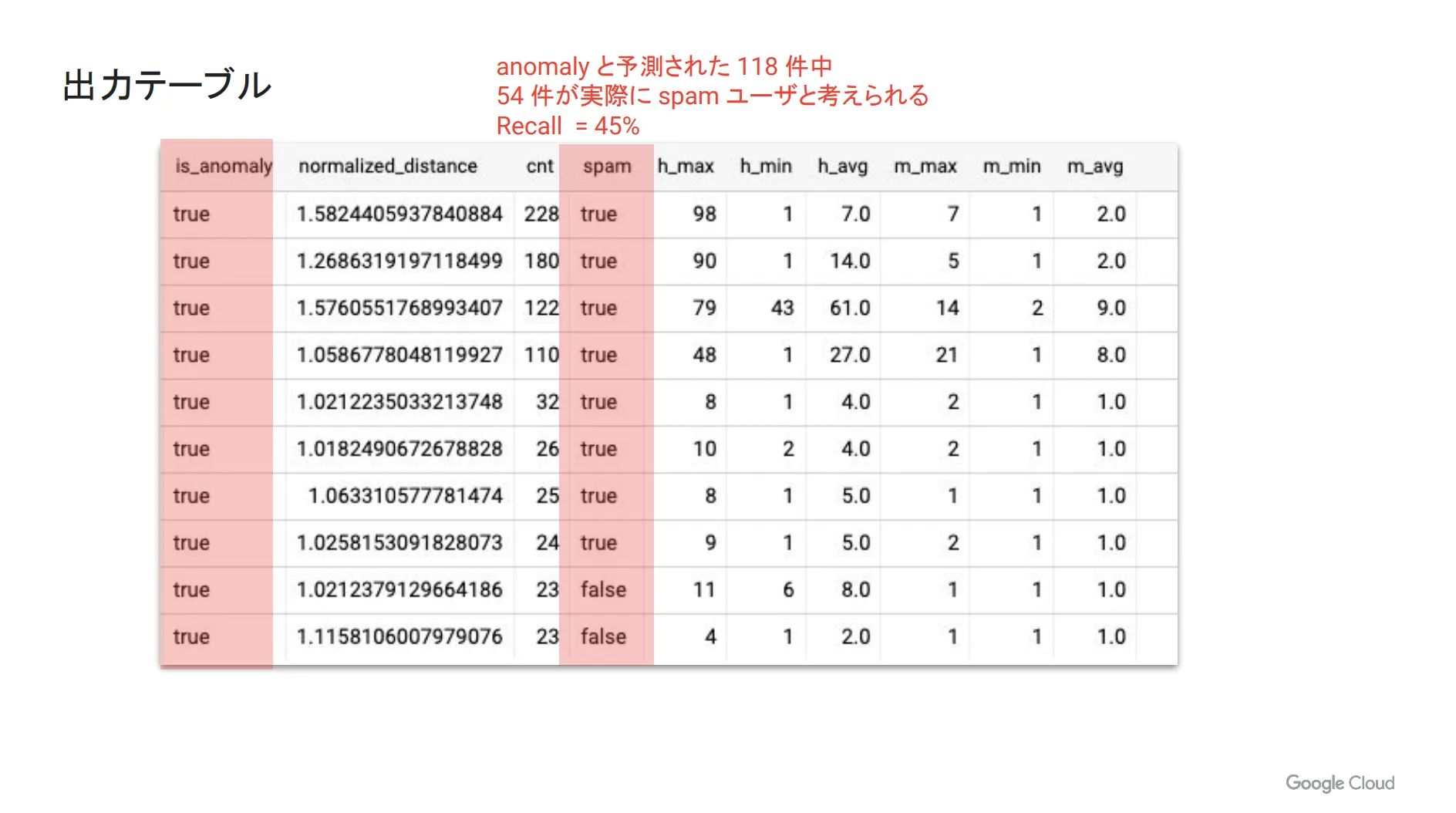
そして、実際に出力されたテーブルが下図になります。今回は、異常値と予測された118件の中で、実際に spam だと考えられるものは54件でした。つまり、 Recall (正しく異常検出できたもの)は全体の45%ということになり、異常検出の精度としては満足できない結果だと言えます。
ハイパーパラメータ調整機能
前項でご説明したような精度改善を実現するため、 BigQuery ML (BQML) はハイパーパラメータ調整機能というものを搭載しています。これを活用することで、先ほどの例で挙げた Recall が45%から75%に大きく改善されました。

このように、 BQML は手間なく異常検出を行うだけではなく、より高精度な検出を実現するための機能を有している点も大切なポイントになります。
オートエンコーダ
オートエンコーダとは?
オートエンコーダは、入力されたデータを後で復元できる状態に圧縮してくれるディープニューラルネットワークの手法です。重要度が高い情報のみを洗い出し、それ以外の情報は排除することで次元圧縮を行う仕組みとなっています。
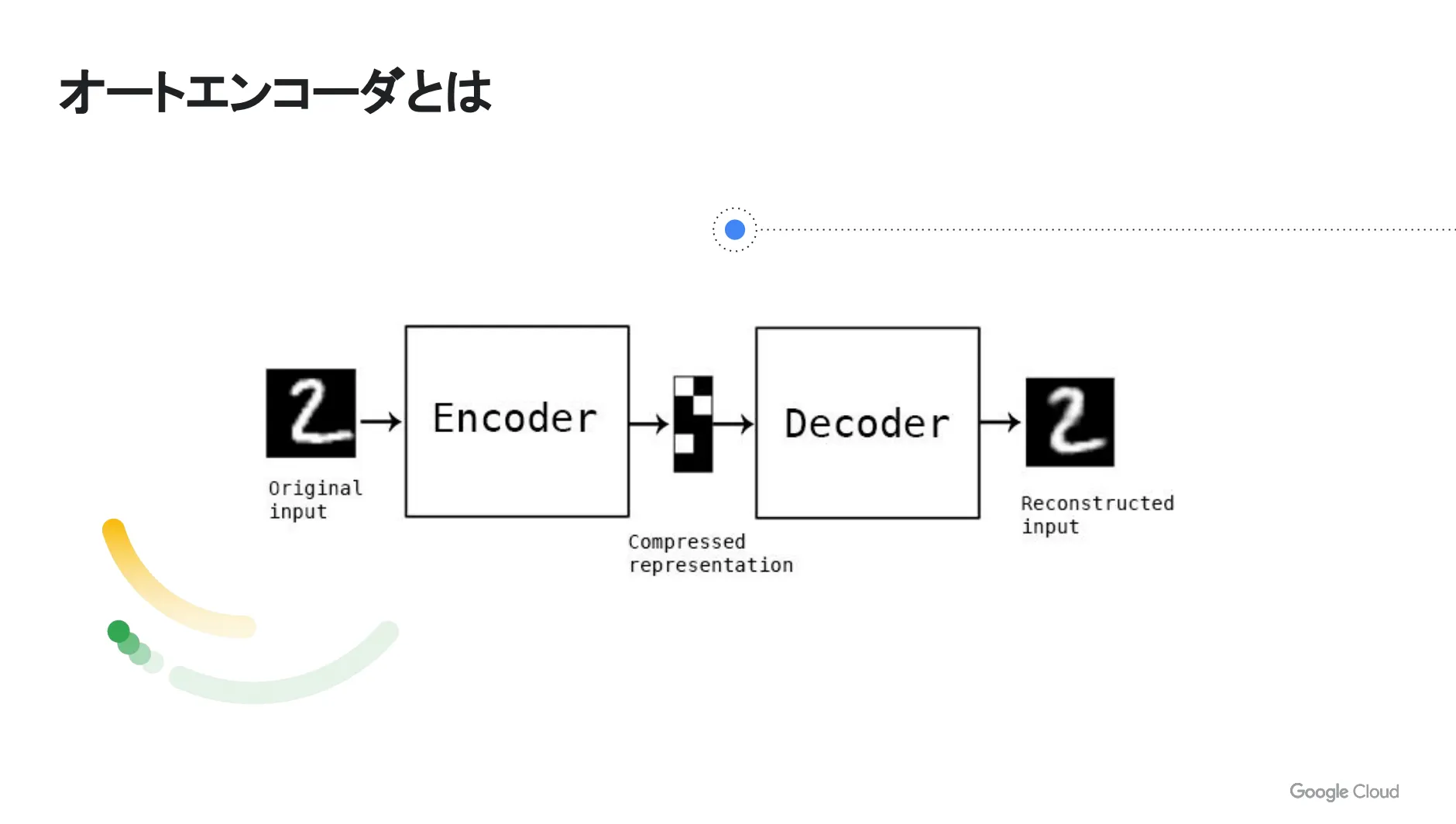
オートエンコーダによる異常検出の考え方
下図は、手書きの数字画像のデータセットでオートエンコーダの処理イメージを示したものです。上が入力データ、下がオートエンコーダで再構築された出力を表しており、下部の赤字で記載されている平均二乗誤差は、入力と出力にどのくらい差があったのか、を示す数値です。
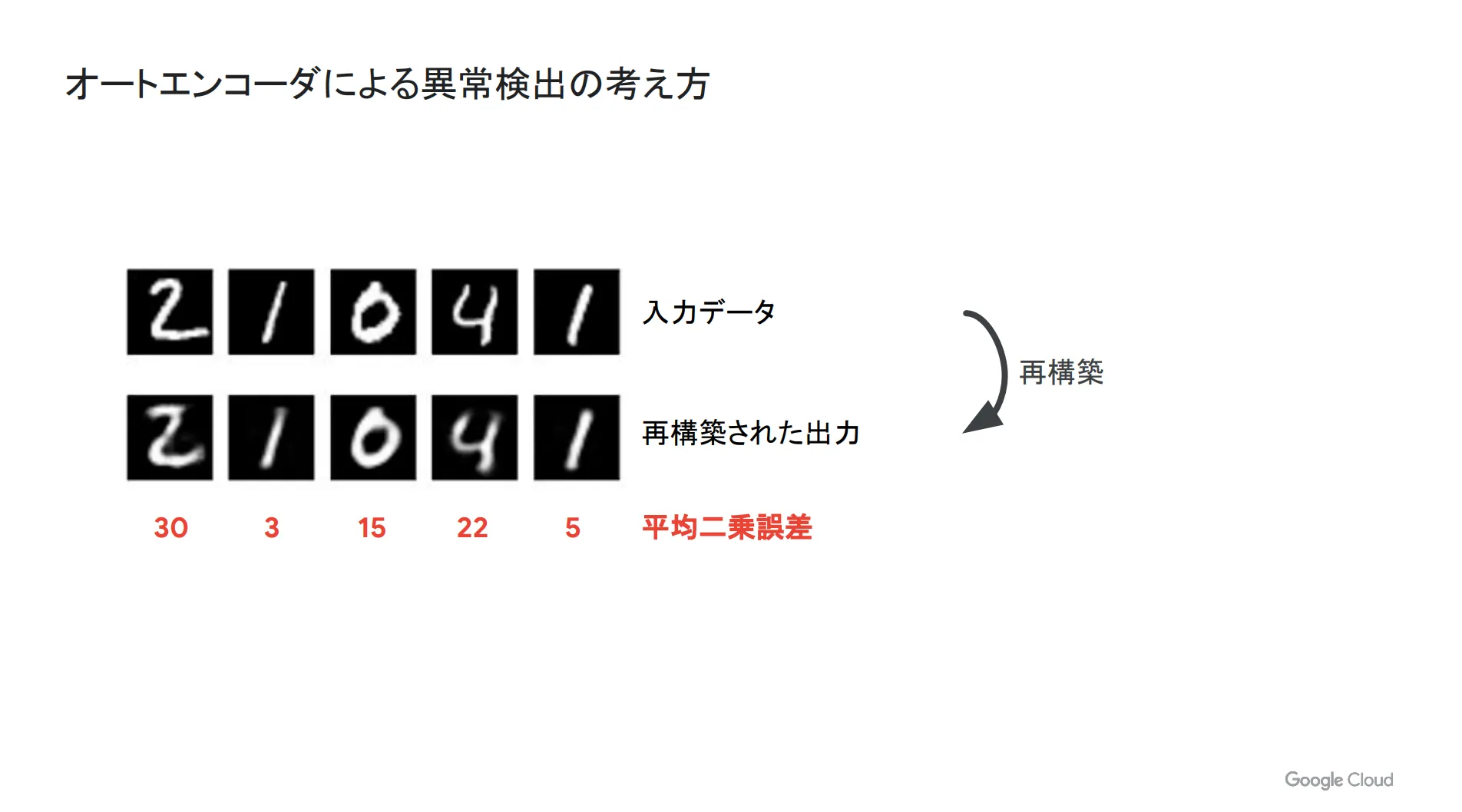
仮に間違えたデータを入力してもオートエンコーダは出力を行ってくれますが、その場合は平均二乗誤差の値が大きくなります。そのため、入力と出力の誤差が大きいものを異常と見なす、というのがオートエンコーダによる異常検出の基本的な考え方です。
contamination パラメータで閾値を設定
オートエンコーダによる異常検出では、 k-means と同様に contamination パラメータを使って閾値を設定します。例えば、 20% を設定した場合は、平均二乗誤差が20以上となっている右の2つは異常として扱われます。

モデル作成
ここでは、オートエンコーダのモデルトレーニングをご紹介します。基本的な SQL 文は、ここまでご紹介した ARIMA_PLUS 時系列モデルや k-means クラスタリングと同様です。モデルタイプは autoencoder を指定し、その下にディープニューラルネットワークの一般的なパラメータを書いていきます。
CREATE MODEL anomaly.autoencoder_model
OPTIONS(
model_type='autoencoder',
activation_fn='relu',
batch_size=8,
dropout=0.2,
hidden_units=[32, 16, 4, 16, 32],
learn_rate=0.001,
l1_reg_activation=0.0001,
max_iterations=10,
optimizer='adam'
)
AS
SELECT * EXCEPT(name,spam)
FROM
anomaly.spam_cnt;
ML.DETECT_ANOMALIES による異常検出
オートエンコーダの場合も ML.DETECT_ANOMALIES で異常検出を行います。 k-means クラスタリングと同様に AS contamination で値を指定します。
#Query for creating anomaly detection results
SELECT
* EXCEPT(name)
FROM
ML.DETECT_ANOMALIES(
MODEL anomaly.autoencoder_model,
STRUCT(0.05 AS contamination),
TABLE anomaly.spam_cnt
)
WHERE is_anomaly = true;
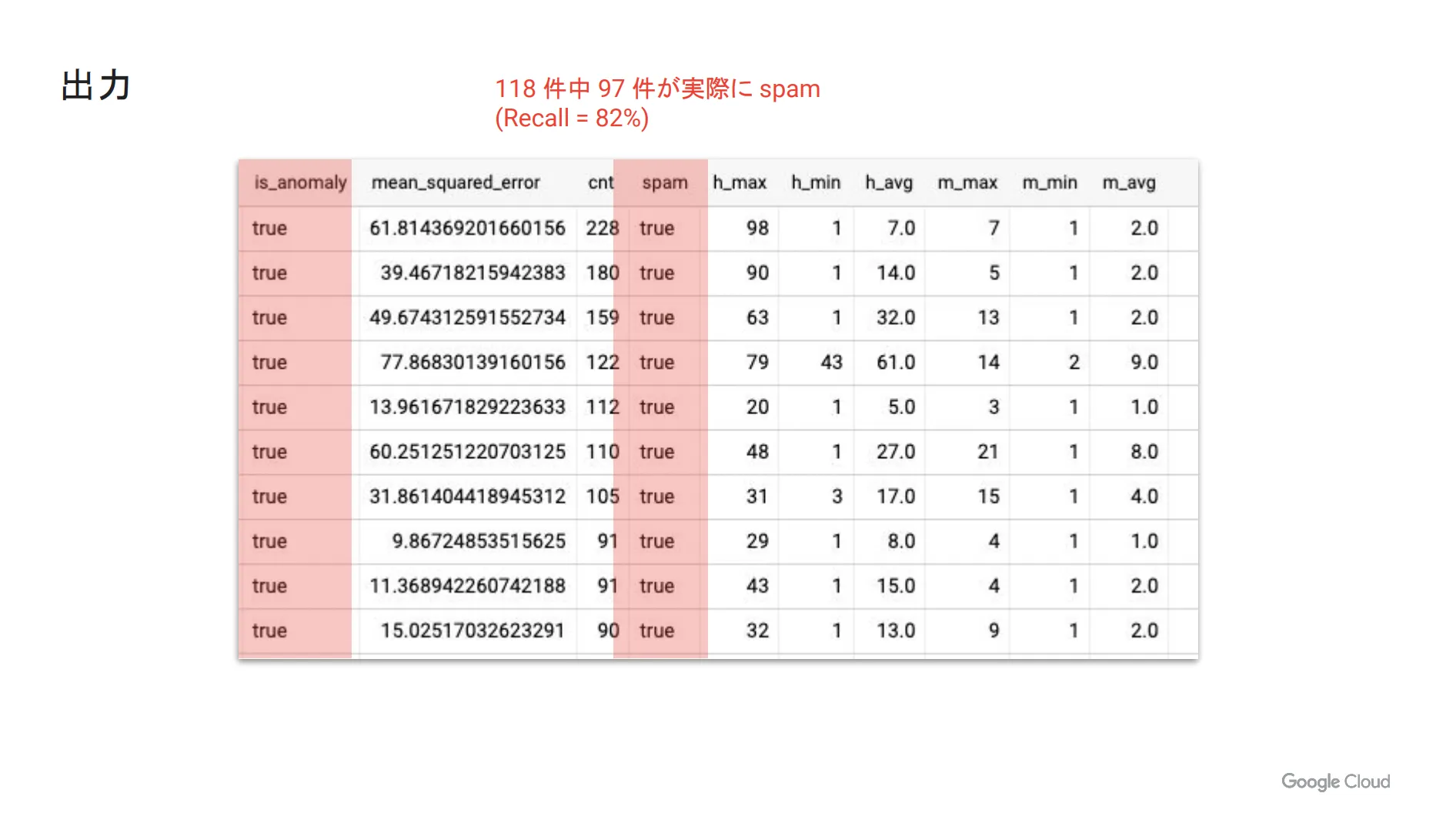
そして、実際に出力されたテーブルが下図になります。今回は、異常値と予測された118件の中で、実際に spam だと考えられるものは97件でした。つまり、 Recall (正しく異常検出できたもの)は全体の82%ということになり、高い精度で異常検出を行うことができました。
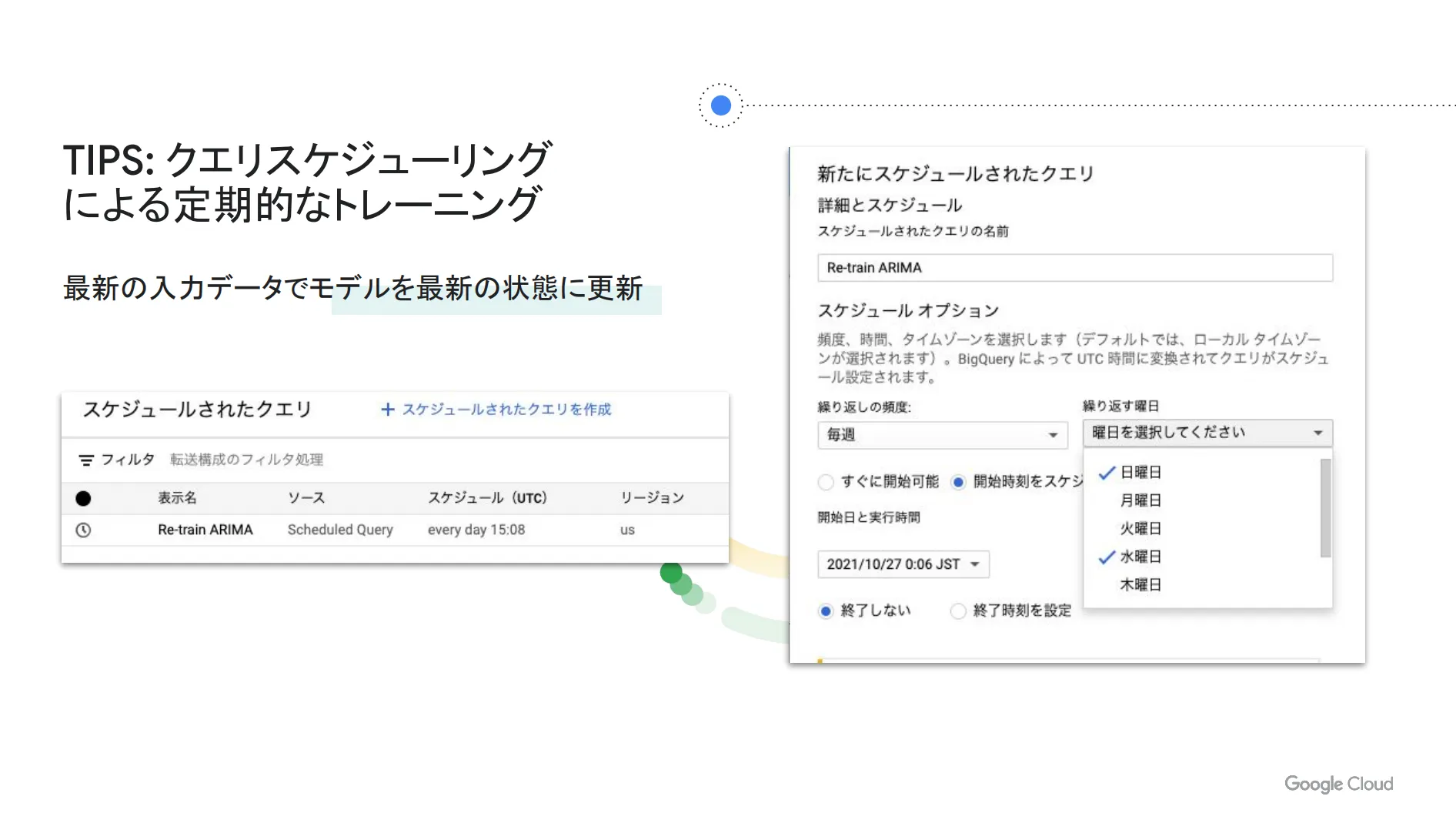
BigQuery ML (BQML) を活用した異常検出の方法は以上となりますが、最後に Tips をご紹介します。機械学習モデルを継続的に使うのは大変だと感じる方もいますが、 BigQuery でクエリのスケジュールを設定することで、最新の入力データでモデルを最新の状態に更新できます。ぜひお試しください。
BigQuery ML に関する Q&A
Q.BigQuery ML を学ぶ上でオススメのドキュメントや資格はありますか?
A.BigQuery ML の専門書籍はありませんが、日経クロステックから「ハンズオンでわかりやすく学べる Google Cloud (GCP)実践活用術」という本がリリースされており、この本の中で BigQuery ML の基本が解説されています。 Google の公式ドキュメントも独学にはオススメです。
Q.ARIMA で異常検知する場合、異常値が含まれているデータでモデルを作成しても大丈夫ですか?
A.BigQuery ML の ARIMA_PLUS モデルには、外れ値をクリーンアップする機能が搭載されているため、異常値が含まれていても問題ありません。
Q.BigQuery ML による異常検出の事例はありますか?
A.海外のホテルにて、予約サイトの入力データに異常がないかをチェックするために k-means クラスタリングを活用している事例があります。
Q.既存のモデルにデータを追加してアップデートしたり、モデルを継続的に育てたりすることはできますか?
A.モデルのアップデートは可能ですが、強化学習などで継続的にモデルを育成するような機能はありません。
Q.contamination の値はどのように決めれば良いですか?
A.データ全体を俯瞰し、異常値の割合を踏まえて決めることが多いです。100%の正解はないので、自社のビジネスニーズに合わせて適切に設定することが大切です。
Q.デモは Workbench を使っていますか?
A.はい、 Workbench を使っています。従来の AI Notebook よりも効率的に作業を進められます。
まとめ
本記事では、 Google Cloud (GCP)に搭載されている BigQuery ML (BQML) を活用して、教師ラベルなしで異常検出する方法をご紹介しました。内容をご理解いただけましたでしょうか。
以下、今回の内容を図でまとめます。まずは時系列データか否かで判断し、時系列データの場合は ARIMA_PLUS 時系列モデルを選択してください。時系列データではない場合は、状況に合わせて k-means クラスタリングまたはオートエンコーダを選ぶ形になります。
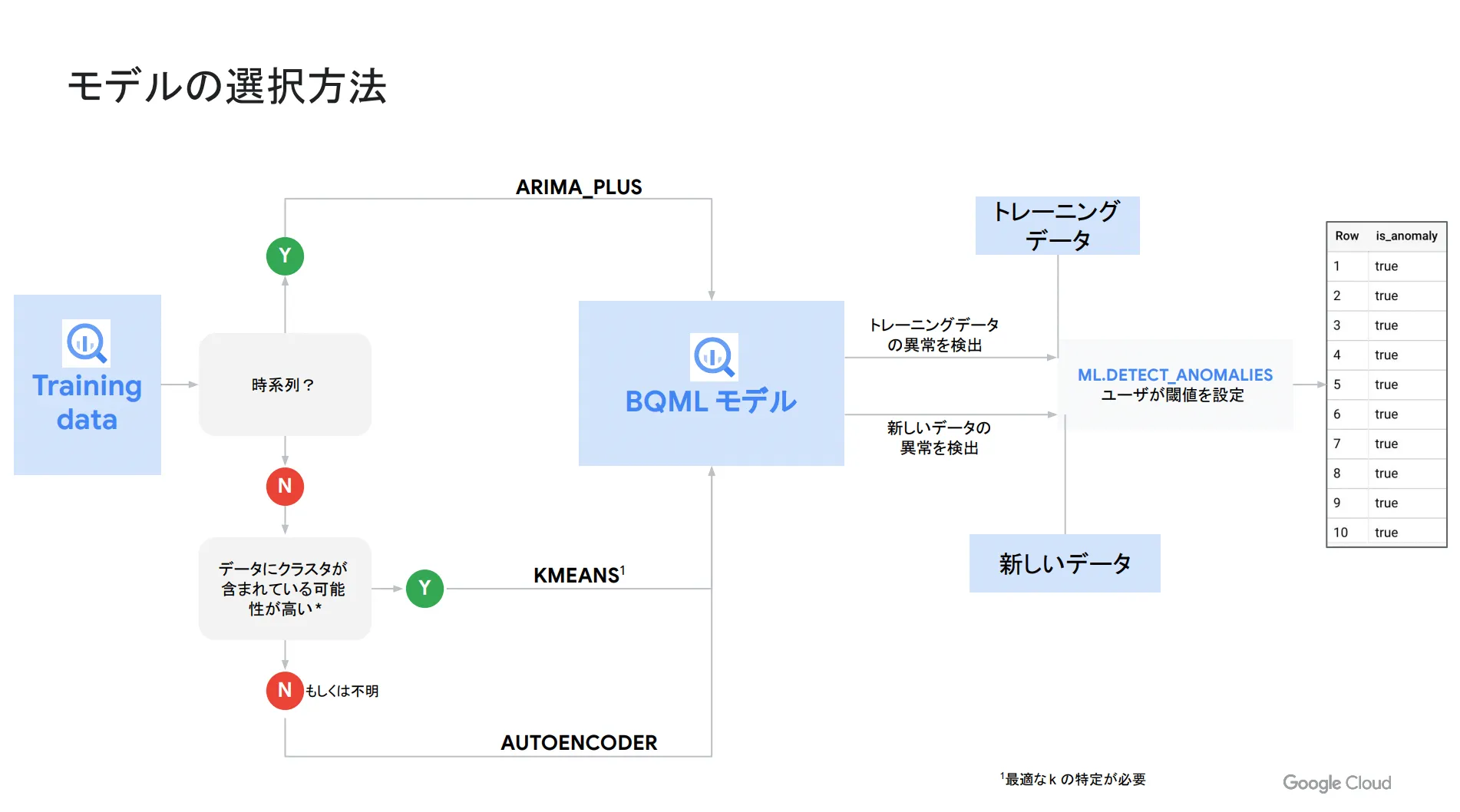
また、 ARIMA_PLUS 時系列モデルは anomaly_prob_threshold に信頼区間を設定し、 k-means クラスタリングやオートエンコーダは contamination に閾値を設定します。
今回ご紹介したように、 k-means クラスタリングよりもオートエンコーダの方が初期精度は高いと言えますが、オートエンコーダは時間がかかる点がデメリットです。なお、 k-means クラスタリングもハイパーパラメータチューニングを行うことで、精度改善が可能になります。
このように、 Google Cloud (GCP)の BQML を活用することで、専門知識がなくても SQL で機械学習モデルを簡単に構築できます。扱うデータや状況に合わせて、利用するモデルを柔軟に選べる点も嬉しいポイントです。
そして、 Google Cloud (GCP)を導入するのであればトップゲートがオススメです。
弊社トップゲートでは、Google Cloud (GCP) 利用料3%OFFや支払代行手数料無料、請求書払い可能などGoogle Cloud (GCP)をお得に便利に利用できます。さらに専門的な知見を活かし、
- Google Cloud (GCP)支払い代行
- システム構築からアプリケーション開発
- Google Cloud (GCP)運用サポート
- Google Cloud (GCP)に関する技術サポート、コンサルティング
など幅広くあなたのビジネスを加速させるためにサポートをワンストップで対応することが可能です。
Google Workspace(旧G Suite)に関しても、実績に裏付けられた技術力やさまざまな導入支援実績があります。あなたの状況に最適な利用方法の提案から運用のサポートまでのあなたに寄り添ったサポートを実現します!
Google Cloud (GCP)、またはGoogle Workspace(旧G Suite)の導入をご検討をされている方はお気軽にお問い合わせください。
メール登録者数3万件!TOPGATE MAGAZINE大好評配信中!
Google Cloud(GCP)、Google Workspace(旧G Suite) 、TOPGATEの最新情報が満載!